Lecture 12. 内存管理与缓存策略
https://blog.csdn.net/dongyanxia1000/article/details/53392315 https://www.cnblogs.com/gintaberry/p/4145333.html
访问局部性 locality of reference
访问局部性(英语:Locality of reference)指的是在计算机科学领域中应用程序在访问内存的时候,倾向于访问内存中较为靠近的值。
访问局部性分为两种基本形式,一种是时间局部性,另一种是空间局部性。时间局部性指的是,程序在运行时,最近刚刚被引用过的一个内存位置容易再次被引用,比如在调取一个函数的时候,前不久才调取过的本地参数容易再度被调取使用。空间局部性指的是,最近引用过的内存位置以及其周边的内存位置容易再次被使用。空间局部性比较常见于循环中,比如在一个数列中,如果第3个元素在上一个循环中使用,则本次循环中极有可能会使用第4个元素。第三种为循序局部性。
局部性是出现在计算机系统中的一种可预测行为。系统的这种强访问局部性,可以被用来在处理器内核的指令流水线中进行性能优化,如缓存,内存预读取以及分支预测。
- Temporal 时间:If an item is referenced, it will tend to be referenced again soon
- Spatial 空间:an item is referenced, nearby items will tend to referenced soon.
像这个 hello world 程序,msg1 部分就是空间局部性,循环部分的代码既时间局部性又有空间局部性:

缓存 Cache
当处理器需要内存当中的数据,就会先查找缓存。缓存是 SRAM,很快,主存是 DRAM,慢。如果缓存没有,就会去主存里面找,找到之后就放进缓存,留着备用。然而,存入缓存这个步骤本身,挺慢的。
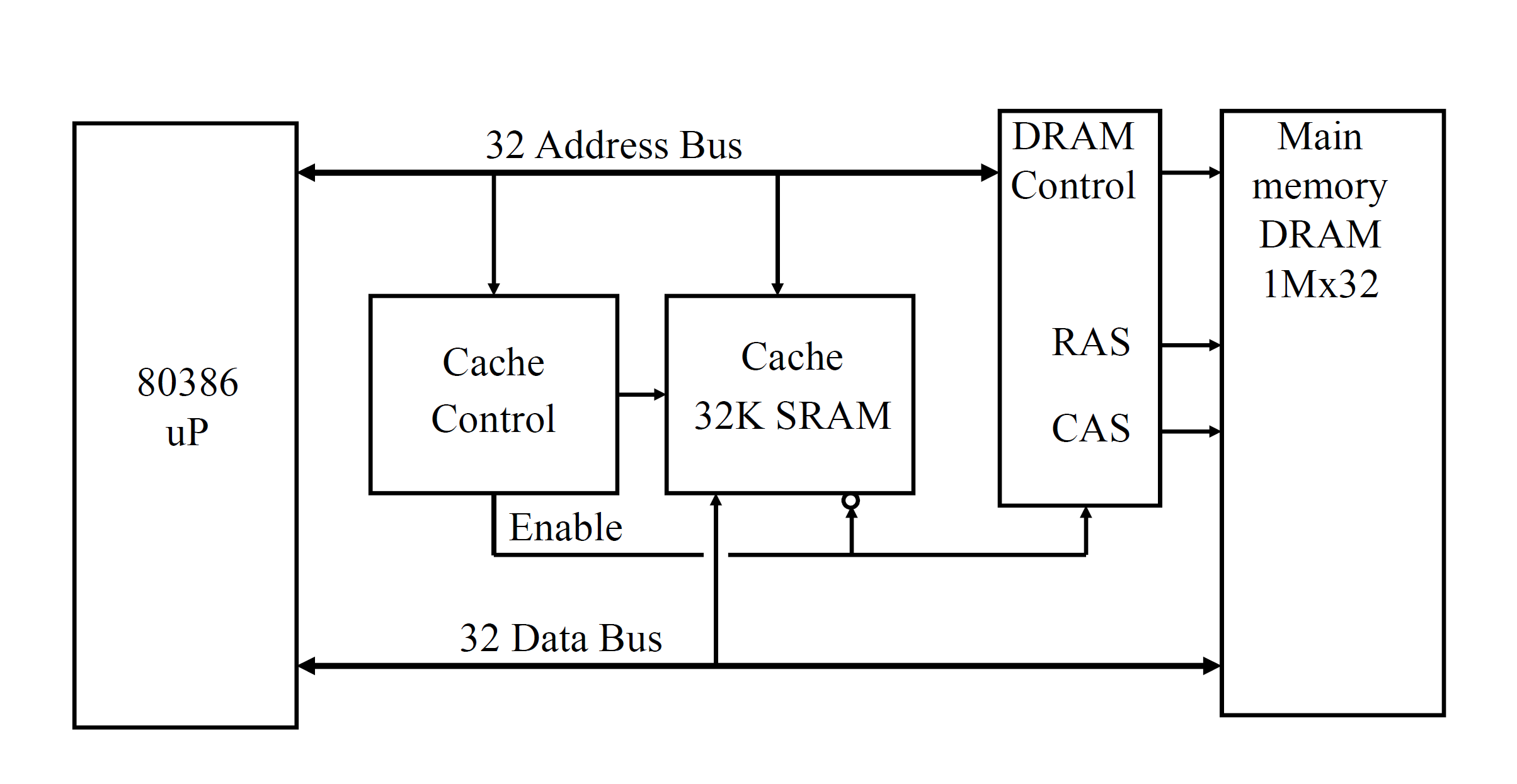
有一个叫做 hit-rate 的东西,定义为 $\frac{SRAM}{SRAM+DRAM}\times 100\%$,这是用于衡量缓存效率的重要指标。一般这个值应当在 90% 左右。
根据经验,如果 hit 了(缓存里有),那么只需要 1~4 个时钟周期。如果 miss 了(缓存里面没有),那就需要 8~32 个时钟周期。而 miss 的概率一般是 1%~20% 左右。
缓存模式
没搞明白,可能有一些错误
- 直接映射 Direct Mapped Cache:缓存对应了主存当中的某个页。如果频繁切换访问的页,那么这种方式就会很慢(thrashing)
- 二路相联映射 Two-Way Set Associative,用两块分开的缓存。这样一来,如果频繁切换访问的页,thrashing 的概率会有所降低
- 全相联映射 Fully Associative,用的时候随便找个缓存位置放进去。但缺点就是如果要查找是否存在,就要遍历一遍缓存(类似停车场,随便停,但是记不住停在哪里,找半天)
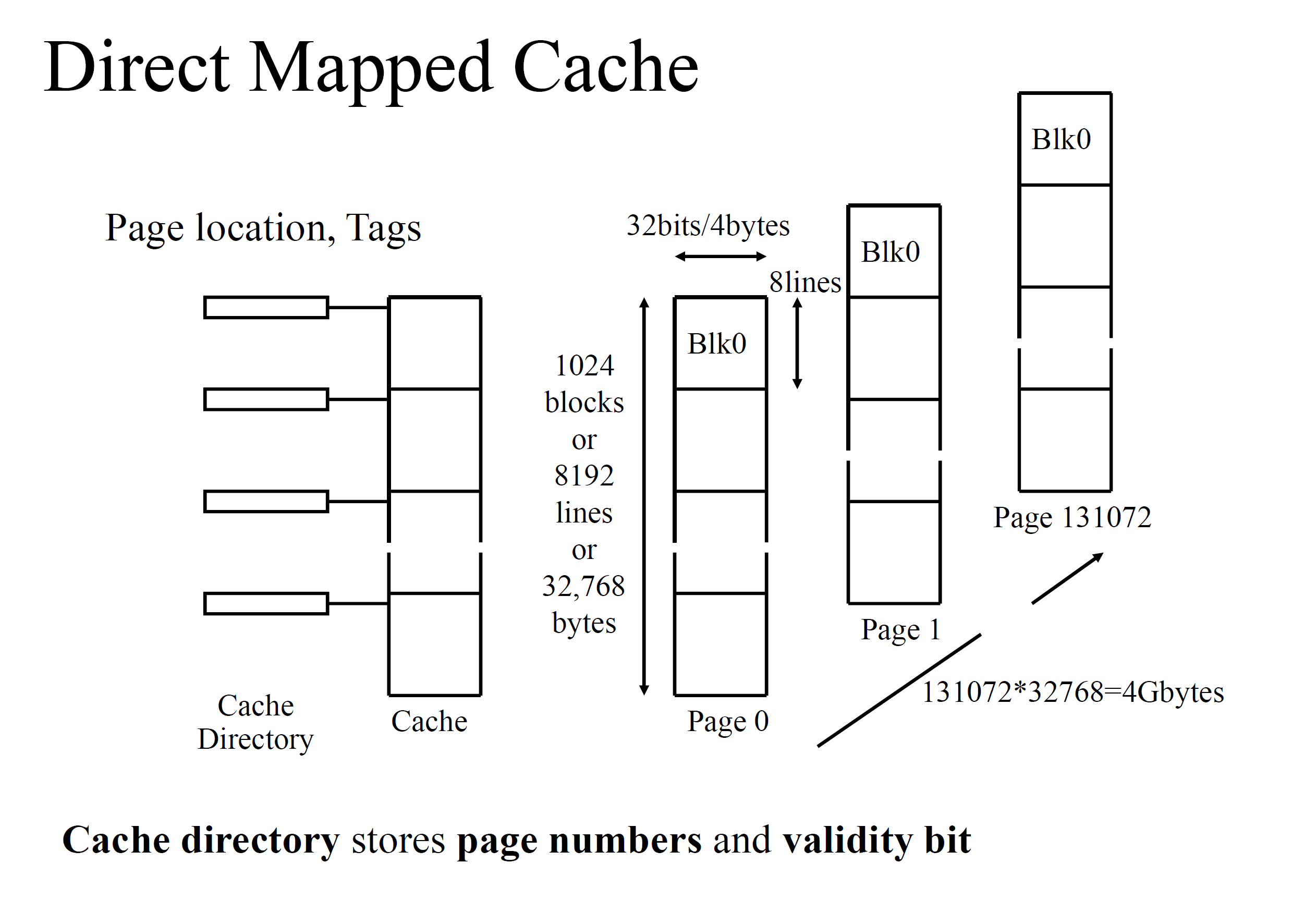
直接映射 Direct Mapped Cache
- 80386,地址总线 32 位,寻址大小 4GB。
- 80386 的缓存包含 8192 条线,每条线都是 4 字节的,所以总共有 32768 个 byte。
- 每条线对应到一个页,那么 4G 的内存就分成了 131072 个页,每页大小 32k
- 由于一共有 131072 个页,所以 32 位地址的高 17 位可以确定页编号,也可以用来判断缓存当中是否有这个数据(还要结合一下 tag bit 判断是否是最新数据)
- 如果 hit 了,就直接从缓存里面拿
- 如果没 hit,就让 cache controller 从 dram 里面拿出来存进 cache
对于 80386 的 32 位的地址总线,因为每个页是 32k 字节或 8k 个线或 1k 个块:
- A15-A31: Set the page in main memory
- A5-A14: Set the block number in cache
- A2-A4: Set the line number in the block
- A0-A1: Specific bytes in the line
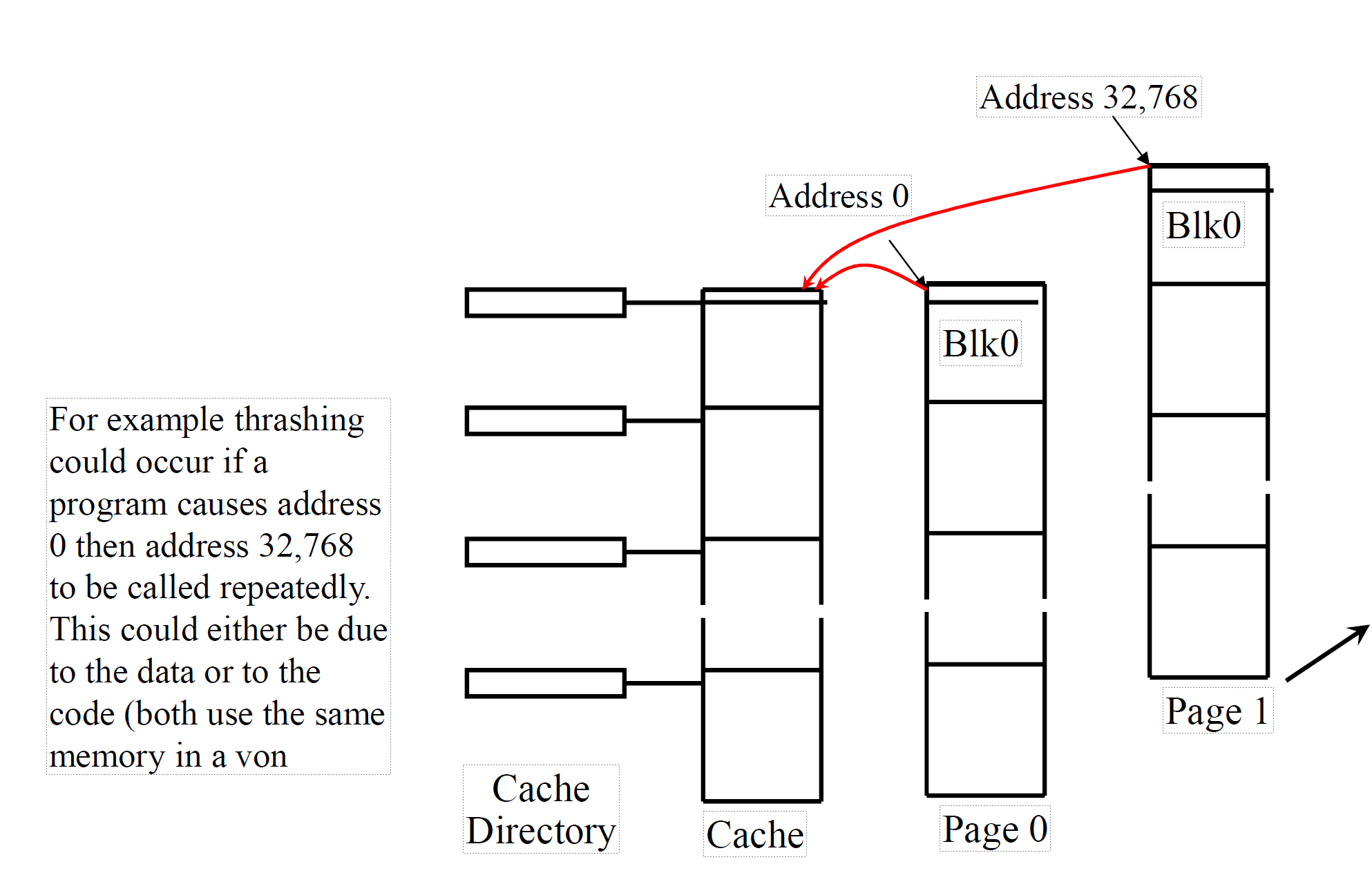
Thrashing
如图,如果先访问 page0 的 blk X,然后 p1 bX,p2 bX,循环下去
每次地址变化都恰好是 32768,就会导致每次访问都刷新一遍缓存,于是导致效率变得很低
二路相联映射 Two-Way Set Associative
- 页数从 131072 变成了 262144,每页的块数减半(从 1024 到 512)
- cache directory 当中的 validity bit 变成了俩,因为有俩缓存
- cache directory 当中新增一个 bit 表示,哪一个是 least recently used 的(LRU)
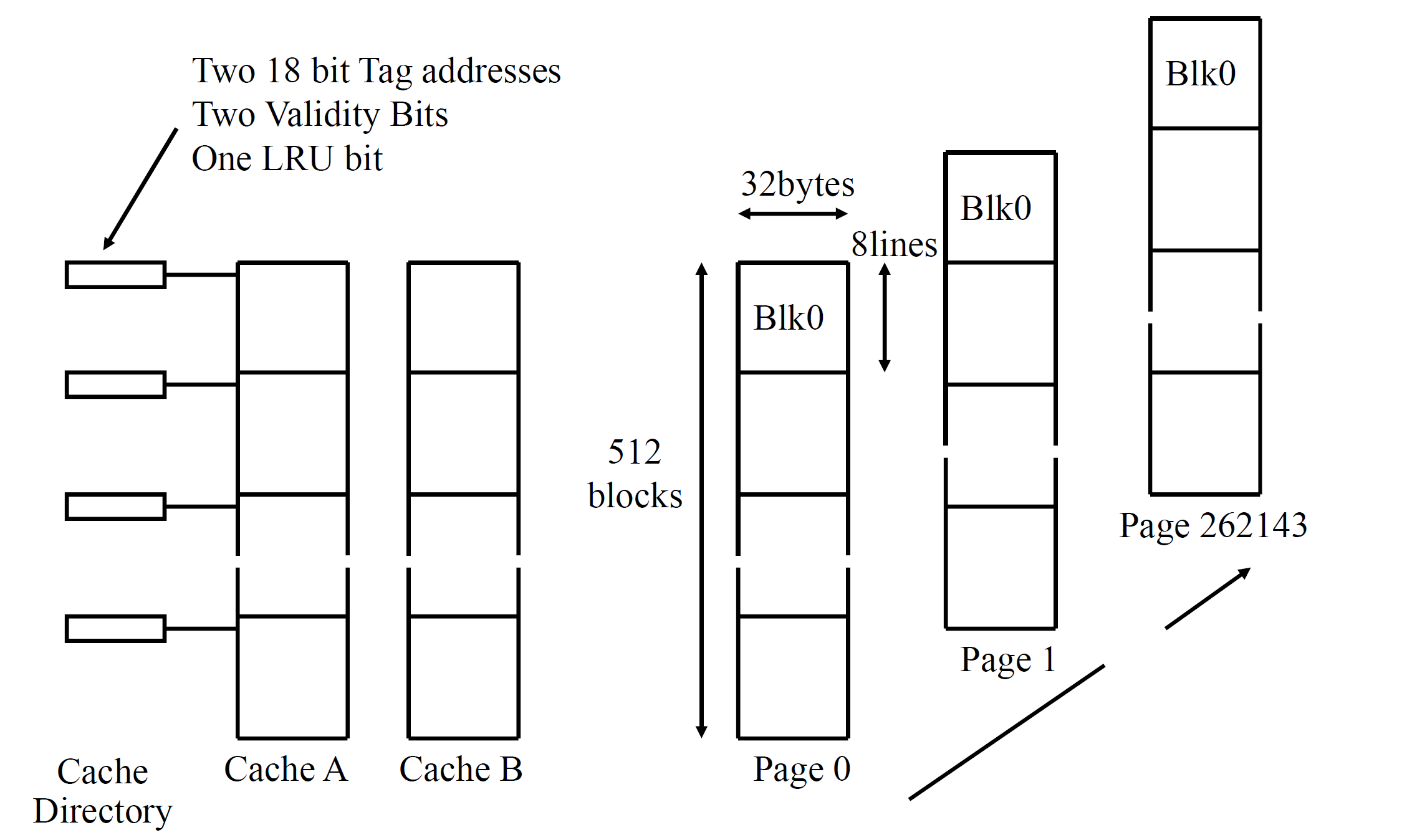
为什么这样可以减少 Thrashing
大概是有两点原因
- 假如缓存 A 已经被占用了,你还可以存到 B 里面
- 假如 AB 都被占用了,你可以根据 LRU 原则,踢掉一个,保留一部分,保留的那些没准就可以减少 miss
全相联映射 Fully Associative
- 每条线(四字节)可以对应缓存的任意位置
- cache directory 当中,tag 必须是 30bits 的
- 正如刚才少说,查找的时候需要遍历
- 当缓存满了,踢掉谁?是随机踢,还是 LRU?
缓存性能
首先考虑什么因素可能导致 miss:
- 某个 block 初次被访问
- 缓存爆满,需要 thrashing
阿姆达尔定律 Amdahl’s Law
阿姆达尔定律,一个计算机科学界的经验法则,因吉恩·阿姆达尔而得名。它代表了处理器并行运算之后效率提升的能力。在这里也可以用来算一算缓存与主存的性能提升。
$$Speedup = \frac{1}{(1-p)+\frac{p}{s}}$$,其中 $s$ 是由于改进的资源而产生的加速,$p$ 是受益于改进资源的部分原来占用的执行时间比例。对应到缓存当中来,$s$ 表示 hit 速度是 miss 速度的几倍,$p$ 表示 hit 的频率。假如缓存要 10ns,主存要 100ns(速度差 10 倍),hit 频率 95%,那么计算得到 $$Speedup = \frac{1}{(1-0.95)+\frac{0.95}{10}}=6.89$$,意味着缓存的引入,相较于仅使用 DRAM,可以带来 6.89 倍的性能提升。
根据概率论的知识,算一下引入缓存之后的期望时间:$$E = 10 \times p+ 100 \times (1-p) = 9.5+5 = 14.5$$,从而加速的倍数是 $$\frac{100}{14.5}=6.89$$,结果与阿姆达尔定律算出来是一样的。
写入策略
缓存是为了加速,但也必须保证与 DRAM 一致。假如这个缓存当中的值要修改,对应的 DRAM 的值也会修改(由于 DRAM 比较慢,所以这个修改也比较慢)。修改后,读取速度还是缓存级别。
还有一种策略是,仅当缓存当中这一部分要被代替了,再去对应的主存进行数据更新。这样效率会更高一点。
多级缓存
现代处理器的缓存都有好多级别,
- primary(第一级)是在微处理器芯片上的,大小普遍 1k-32k 左右,无需 wait states,是最快的
- 二级缓存就会达到 2m 的级别,但是频率可能只有 500mhz 了
8086 上的直接内存访问(DMA)技术
DMA 技术在 Frame grabber(录屏卡)和声卡当中比较常用,就是直接向 memory 写数据,节省很多 CPU 时间。
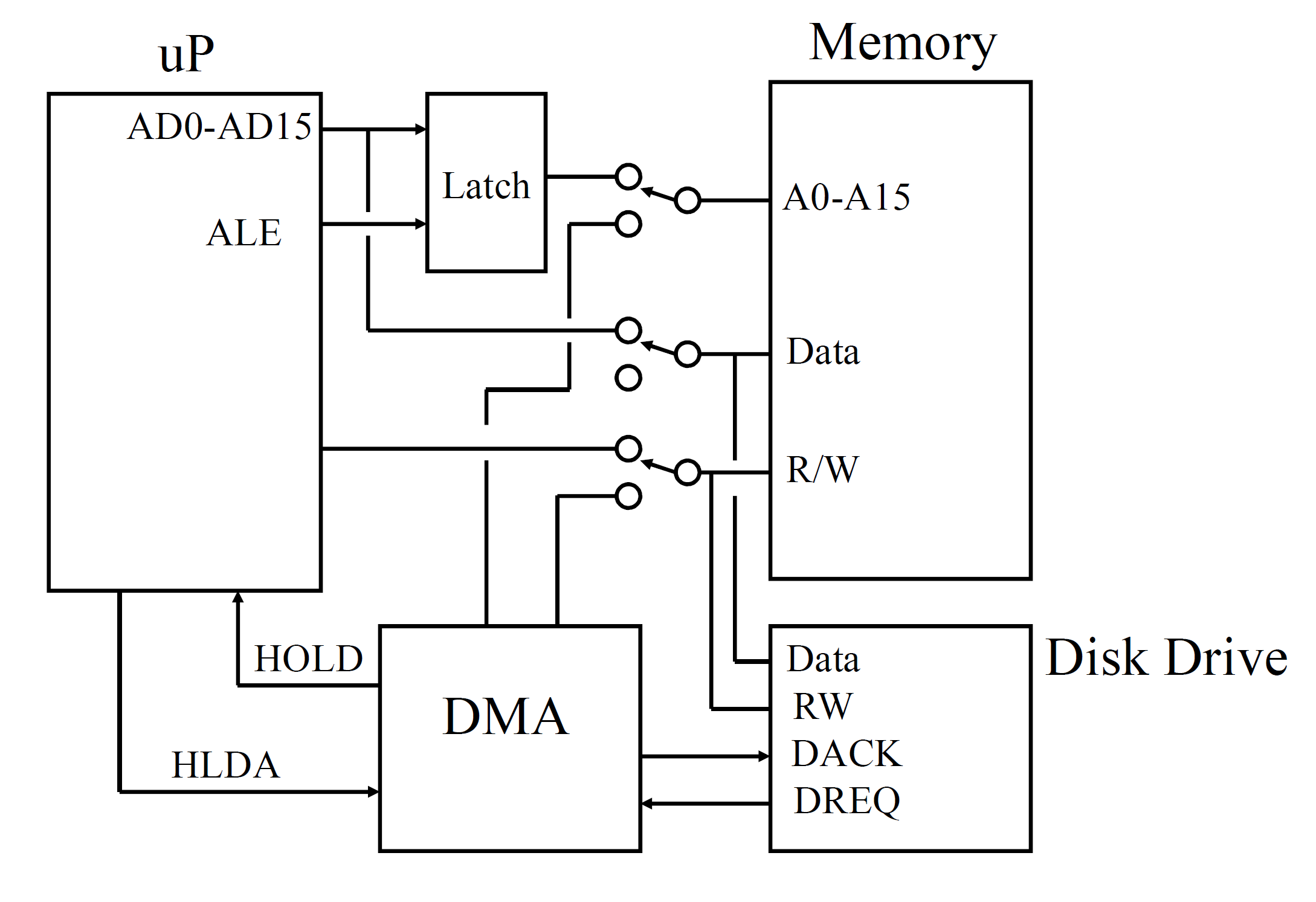
反正大概就是,用一堆信号实现了如下交流:
- DMA 设备告诉处理器,我要用一会存储设备,你别来捣乱!
- 处理器说,好!
- 然后相应设备开始写啊读啊。
- 弄完之后告诉处理器说完事儿了
- 然后处理器重新获得对存储设备的读写权限
ROM 只读存储器
是一种非易失的存储,通常用于存储 BIOS 和 Boot 代码。
ROM 很慢,所以有时候 ROM 的数据会被复制到 RAM 里面去。
有好多类型:
- Mask Programmed ROM,出厂啥样就啥样,没法改
- PROM,Programmable ROM,可以编程一次,就是把设备里面的保险丝(fuse)熔断掉(programmed by blowing fusible links)
- EPROM,erasable programmable ROM,可擦除可编程 ROM。由一堆带电荷的 FET 构成。写起来有点麻烦,需要用高压电(强行改变 FET 的内部电子分布)使之带上电荷;擦除的话,就是用紫外线灯照射,照射之后电荷就没了。
- EEPROM,electrically erasable programmable ROM,电可擦可编程的 ROM。Programmed and re-programmable electrically,比较方便。
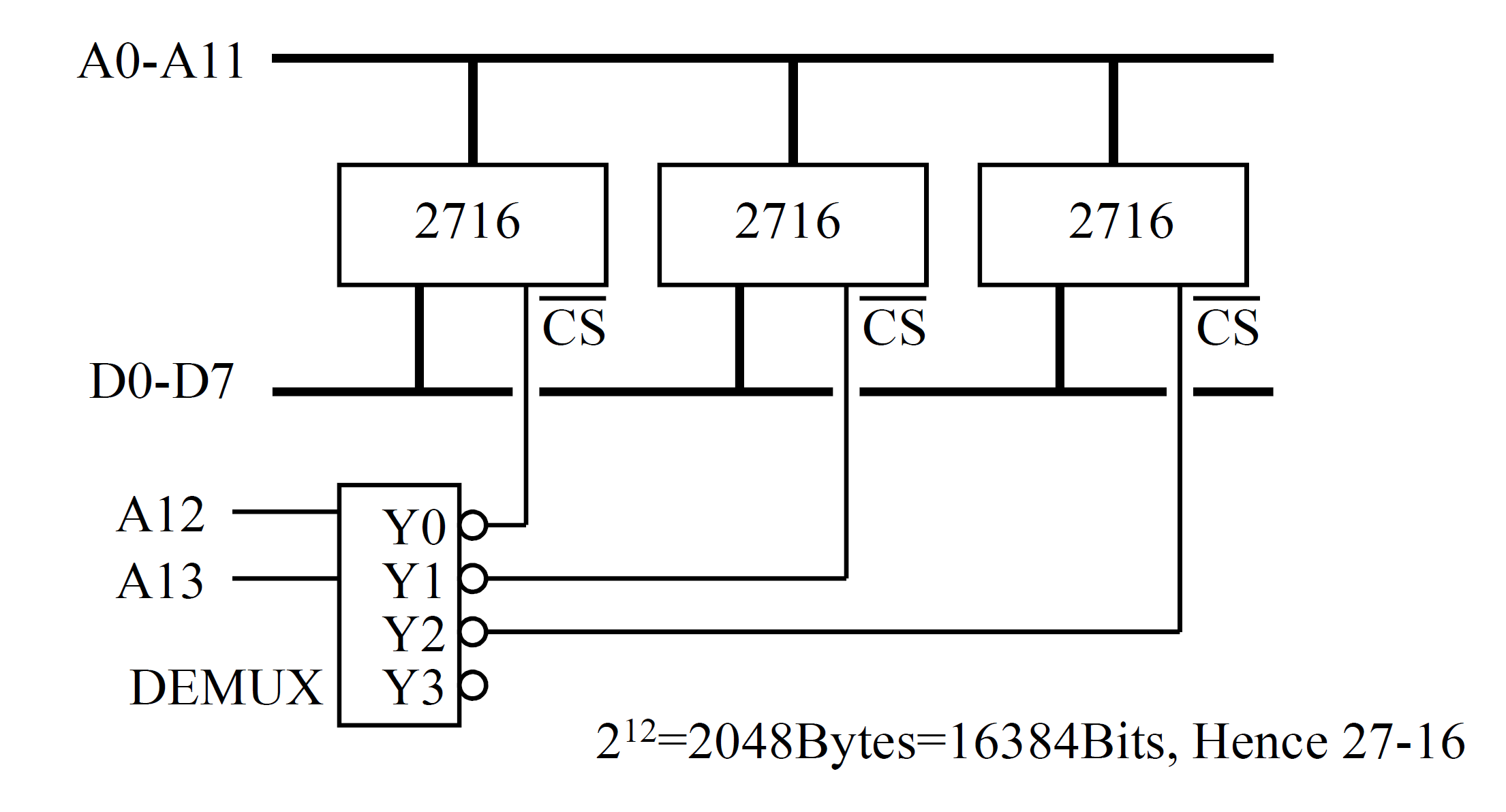
2716 EPROM
2716 是一个 EPROM 芯片的编号,芯片有 24 个引脚。
有一个引脚叫做 CS(Chip Select)。用多路分配器配合 CS 线,就可以把一堆存储设备整合到一起使用:
虚拟内存
一台 32 位的电脑,可以使用的真内存,是 4G,但是这可能不够用,所以就有了虚拟内存的概念。
虚拟内存就是被 CPU 映射的一块区域,通常是硬盘等外部设备上,可达 64G。
需要使用的时候,虚拟内存当中的某个页,就被交换到真实内存上。(为了安全,使用虚拟内存前,应当先 clear,以防止恶意代码等)。
但是虚拟内存特别特别慢(miss penalty 高达 100000 周期)。所以内存快满的时候,电脑就会特别特别卡。