Lecture 21.22.23 文件系统(71 页)
文件是相关的信息的集合。存储在 非易失性(non-volatile) 存储器当中。
文件系统把文件映射到存储设备上,并向用户提供访问和操作文件的接口。
本章涉及到的内容有:
- 如何管理和分配空间
- 如何改善访问文件的效率
- 文件如何组织到分层目录中
固态存储器(SSD)具有性能快、耗电低、坚固、噪音小等特点,所以在移动设备上基本都是固态存储器。但是在台式机当中,机械硬盘由于容量大且价格低,很常见。本章所描述的文件系统主要关注机械磁盘(magnetic)。
关于机械硬盘的结构,可以会看 Lecture 6 的内容。
可以认为每个 block 的大小都是相等的,那么磁盘的总容量,就是 block 的个数乘以每个 block 的大小。
文件系统的设计需求
文件系统应当决定每个 block 应当如何分配,以实现性能的最大化,同时保证 文件持久性(file persistence) 和 数据完整性(data integrity)。
文件系统的用户比较关心的是,如何访问文件,如何组织文件的内部结构,如何给文件进行分组,以及如何与其他用户分享文件。
于是,文件系统应当满足如下要求:
- 把文件映射到存储设备上
- 将文件组织到目录 directory 中
- 能保护文件、能分享文件
- 保证数据完整性和持久性
- 要支持不同类型的存储设备
- 提供用户接口
而文件系统需要提供的接口应当有:
open()close()create()delete()copy()rename()getAttr()setAttr()
其中,attr 属性包含很多信息,比如创建日期、修改日期、读写执行的权限等
文件的组织
像简单的文本文件,就没有啥组织结构,只是一堆字节而已。
也有的文件可能被组织成了若干个大小固定的 record,每个 record 包含不同的信息(比如 png,就有文件结构,分了好几个部分)。文件系统一般都会对这些 record 提供索引、搜索、更新的接口,而不是在字节的层面上。
对于结构化的文件,文件系统可能还会提供如下接口:
retrieve(),表示从文件当中提取一个或多个 recordupdate(),修改一个 recordinsert(),在文件当中添加一些新的 recordremove(),删除指定的 record
文件目录
电脑的文件系统可被形象地看作一个文件“橱柜”。在它之中,高等的目录中有“抽屉”,低等的子目录中可能有“抽屉”中的文件夹。
有了文件目录,就可以更轻松地找到文件在哪里了。每个文件都在目录当中拥有自己的 entry,其中包含文件名、大小、权限等信息。
接下来从一个例子来理解文件系统。
用来理解基本文件 IO 的例子
为了让计算简单,block 和 record 的大小都是特意构造的。实际中的情况要比这个例子复杂得多
例子的描述
- 有一个文件,由 11 个 record 构成,每个 record 都是 250 字节,总大小 2750 字节。
- 这个文件存储在一个只有 16 个物理块的硬盘上,每个块的大小都是 1000 字节。
-
现在我们想要从文件当中读取第 6 个 record 的内容。
-
read(file, record=6, dest=buf, numBytes=250);
最简单的情况下,文件是连续存储在几个相邻的块当中的。
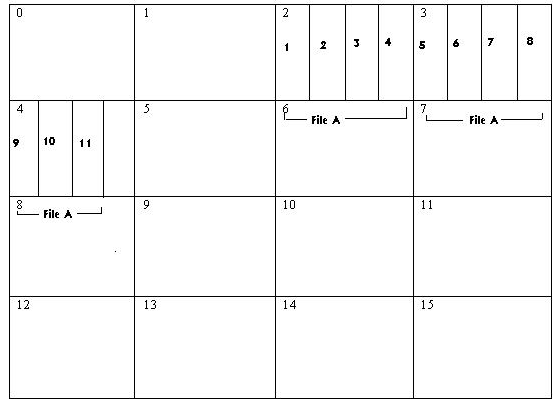
如何读取这个例子的数据
于是为了读取这个文件的信息,文件系统必须先找到这个文件的物理位置在哪里,然后再去找第 6 个 record。
为了便于访问这个文件 A,应当在目录当中包含如下内容(现在还是假设连续存储)

在连续存储的条件下,只要第一个 block 的位置确定了,文件的大小和物理 block 的大小也确定了,那么就可以计算出,存储了这个文件的其他的块都有哪些。
于是,文件系统就会在目录当中查询,fileA 的起始位置。查到了,是第 2 个块. 然后就可以计算出 record 6 在第几个 block(3),然后进去读取。
注意,文件系统的视角是 physical 的,因为文件系统要关注文件在哪几个块里面;而对于应用程序,只是 logical 的视角,因为只需要关注这个文件有多少个 record 以及每个 record 是多大。
于是,文件系统先计算出来第六个 record 相对文件的首位置的偏移:$(6-1)\times 250=1250$ 字节。然后发现,$1250 / 1000 \in (1, 2]$,意味着这个 record 在这个文件所占有的第 2 的块。由于这个文件本身就是从物理的第 2 个块开始的,所以加起来,可以得到这个 record 在物理的第 $2+(2-1)=3$ 个块。

然后计算得出,record 6 在这一个块里面的起始位置是 250,结束位置是 499。所以文件系统就会把这一个块的 $[250, 499]$ 这段内容读取出来。
用这个例子分析性能
首先,目录这个东西,肯定也是存储在这个硬盘的某个位置上的(要不然把硬盘装到别的电脑上就读取不了了,那不是闹笑话吗)。
刚才这个读取文件的方法有一个缺点就是在于,它只是针对于读取一个 record。想象一下,如果要读取全部 11 个 record,用这个方法,岂不是计算了好多次位置在哪里?计算一下,对于每个 record 都是先读一遍目录,然后算位置,再从对应的位置读数据。相当于一共读了 22 次!硬盘操作是很慢的!
而且如果文件数量很多,那么目录本身也会比较大,横跨好多个 block。每次从目录里面找到这个文件的信息,可能也要读取更多的 block。那性能就更加糟糕了!必须想办法改善。
在实际当中,文件系统会提供一个函数用来 open() 文件。open() 过程中,会搜索一遍目录,找到文件的位置。然后这个位置就保存下来了,以后不管是读还是写,都不用再从目录里面找了(不过如果是写的话,大小发生变化,可能目录要对应的做一点修改,不过修改是 lazy 的,在 close() 的时候才会写入到硬盘里面去)。于是找目录的次数就从 11 次变成了 1 次,这是第一点优化。
第二点优化,可以利用缓存。就是读到一个 block,就整个的缓存下来。然后每 4 个 record 在一次硬盘读取操作内完成。于是,总共需要的硬盘读取次数从 22 降低到了 $1+3=4$。
用这个例子分析 free space
为了方便用户存储文件,文件系统还应当实时监测 free space 的位置和大小等信息(创建新文件或已有文件的大小发生变化后)。文件系统应当自动算出 free space 在哪里,下一次创建新文件的时候应当自动放到那个位置,无需用户指定。
free space 也可以存到目录里面。比如这个样子

如果创建了一个新文件 fileB,大小 2500 字节,那么目录和硬盘的结构可能就变成了下面的样子(依然假设连续存储)


用这个例子分析动态空间调整
但实际上吧,创建文件的时候是不知道这个文件将来可能有多大的。显然不能在创建一个文件的时候给它一万个 block 的空间吧?那太浪费了。所以应当有一个 dynamic 的分配 block 的方式。
假如这个文件 A,在创建文件 B 之后,又加入了两条 250 bytes 的 record,那么这个文件就变成了 3520 个字节,需要四个 block 了。
假如还是要使用连续存储的方式,加两条 record 就必须移动一部份文件。要么把 B 挪到后面去,要么把 A 挪到后边去。一般挪 A 比较简单(因为后面可能不只是 B,还有 CDEF 要挪)。挪走之后,A 之前占据的三个 block 就变成 free 的了。
于是硬盘结构和目录变成了下面的样子。


链接分配
刚才一直在用 连续分配(contiguous allocation) 的方式,这种方式的优点就是目录的结构比较简单,而且所在位置也比较容易计算。但缺点就是,假如文件的大小一直在变,那可能就要一直不停的挪挪挪,严重降低效率。
链接分配(linked allocation) 可以连续分配的所有问题。
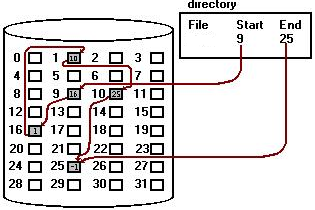
链接分配的目录里面有一个指向链表首元素的指针,也就是指向第一个 block 的指针。然后,每一个 block 还包含了指向下一个 block 的指针。而最后一个 block 包含了一个特殊的指针 EOF,表示链表结束。
这样的话,每一个 block 里面都需要一点点的空间来存储指针。这一点点的位置将不能再存储用户的数据。
同样的,free space 也可以用链表来存。
优缺点分析
对于连续访问(sequential access),链接分配可以有很好的性能,因为读取完一个 block 之后立即根据指针跳到下一个,不需要不停的找位置。
但是对于随机访问(random access),链接分配的性能就不好了。因为要找到想要读取的位置,可能需要遍历整个链表,而遍历链表需要就是从硬盘里面读取指针。
而且需要占用额外一点小空间来存放指针,这也是缺点之一。
还有一个缺点,就是链接分配的鲁棒性不如连续分配。假如有一个 block 因为物理原因损坏了,那么这个 block 里面的指针信息可能就没了,那么后面的所有的东西可能就都找不到了。
链接分配的变种:FAT
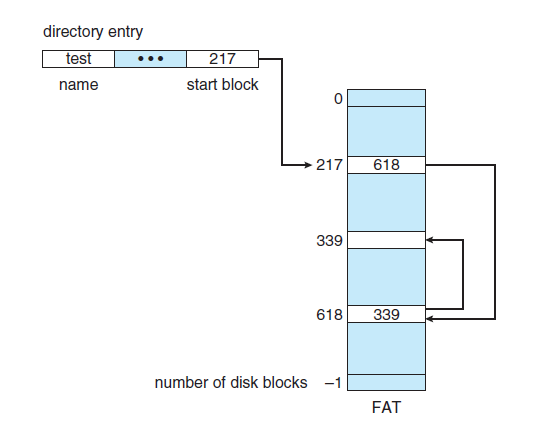
FAT 是文件分配表(file allocation table)的意思。说白了就是把链表单独存到一个表里面了。
进行随机访问的时候,先把这个 FAT 读到内存或者缓存里面,然后就不需要在硬盘里跑来跑去找东西了。
但是一旦 FAT 这个部分被损坏,整个盘可能就废了。所以最好备份一下这个 FAT 到一个固定的位置去。
索引分配
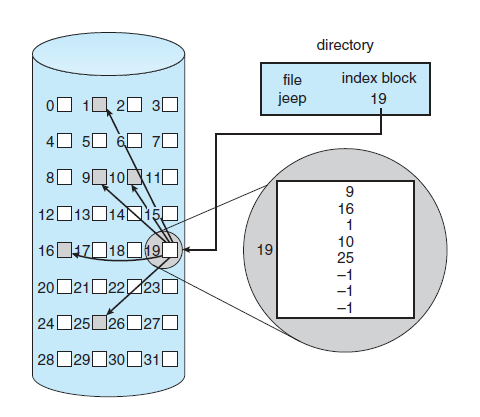
索引分配(indexed allocation) 也是一种解决链接分配随机访问效率低下的方式。索引分配把所有的指针都放在一起(索引块,index block)。
每个文件都有一个索引块,索引块是一个数组,数组当中的第 $i$ 个元素存储了这个文件的第 $i$ 个 block 的物理位置。
目录当中会包含文件索引块的指针。然后按照索引块依次读取就好了。
优缺点
无论是对于随机访问还是顺序访问,索引分配的性能都挺不错的。因为它只需要根据目录指示的位置,读一次索引块就好了。
然而缺点还是要占用额外的空间来存储索引块。如果小文件太多的话,存储的效率可能不怎么好。
同样的,如果索引块被损坏了,那么整个文件可能也读取不了了。
如何选择分配方法
文件系统对于不同类型的文件会采用不同的分配方法。
像大小固定不变的静态文件,就可以使用连续分配的方法,最省事儿了,而且效率也很不错。比如可执行文件,一经编译,大小固定,而且一旦读取基本上就是整个文件全都读一遍。
对于大小比较动态的文件,可以用 FAT。
像大型的数据库文件,通常需要频繁的随即访问,所以会使用索引分配的方式,来解决性能和高效空间分配的问题。
分层结构:文件夹
如果一个目录包含了所有的文件,就是 flat name space。在这种情况下,如果文件太多的话,给每个文件起一个独一无二的文件名,挺难的。就算把名字起好了,这个名字可能也不好记。因此,应当搞一个文件夹,把相关文件放到一起。这样不仅对文件系统比较友好,对用户也更加易于使用。如有必要,还可以搞子文件夹(子目录)。
对文件目录做一下修改,增加一列表示文件的类型,有特殊、普通文件、文件夹三种取值。
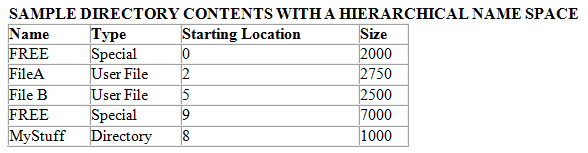
有了文件夹的分层结构,不同文件夹下的文件名就可以重复了。因为可以用 path/name 的格式来唯一的指定文件。
既然有了文件夹这个概念,那就得有「根」的概念。整个文件系统里面所有的文件夹和文件差不多构成了一个树形结构,根节点就是根目录,即上图所示。
当前目录与搜索路径
但是把,假如文件夹分了好多好多好多层,那么用 path/name 的格式来指定文件,那可能就特别特别特别长。于是就有了 当前目录(current directory) 的概念。就是说,如果没有使用 path/name 的格式而是 name,那就相当于是查找 curDir/name 的文件。
但是这样好像还不太够,于是又有了 搜索路径(search path) 的概念,就相当于环境变量。如果 curDir/name 不存在,那就从所有的环境变量里面,依次寻找 PATH/name。
还是不太够。Unix 和 Windows 上还提供了 . 和 ··,分别表示当前目录和上级目录。
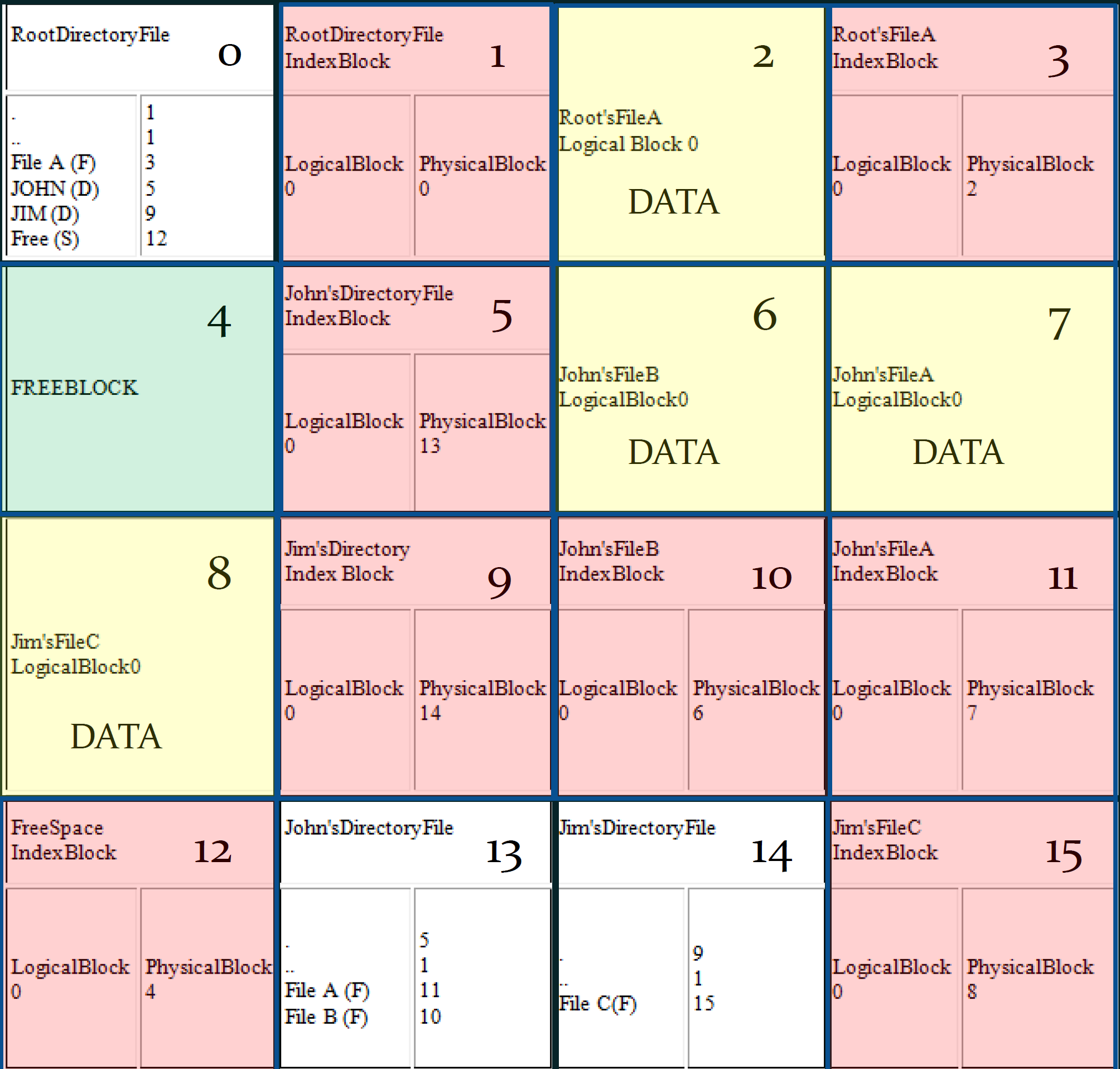
例子:使用索引分配来找文件和文件夹

这个结构,一个根目录,俩文件夹,四个文件。所以需要总共 7+1 个索引块,表示这些文件和 free 位置。
为了方便,假设 file ABCD 都只占用 1 个 block。
于是硬盘的结构是这个样子:黄色表示文件,红色表示索引块,白色灰色表示目录,绿色是 free
UNIX 的文件系统
我觉得这里不会考,所以决定先不看了。