Lecture 18. 引入内存管理(28 页)
冯诺依曼和哈佛架构
有一个叫做 存储程序计算机(stored-program-computer) 的概念:一种将程序指令存储在电子或光学可访问存储器中的计算机。经常扩展该定义,要求内存中程序和数据的处理可以互换或统一。
冯诺依曼架构(von Neumann architecture),就是一种存储程序计算机的模型,也是现代计算机的结构基础。
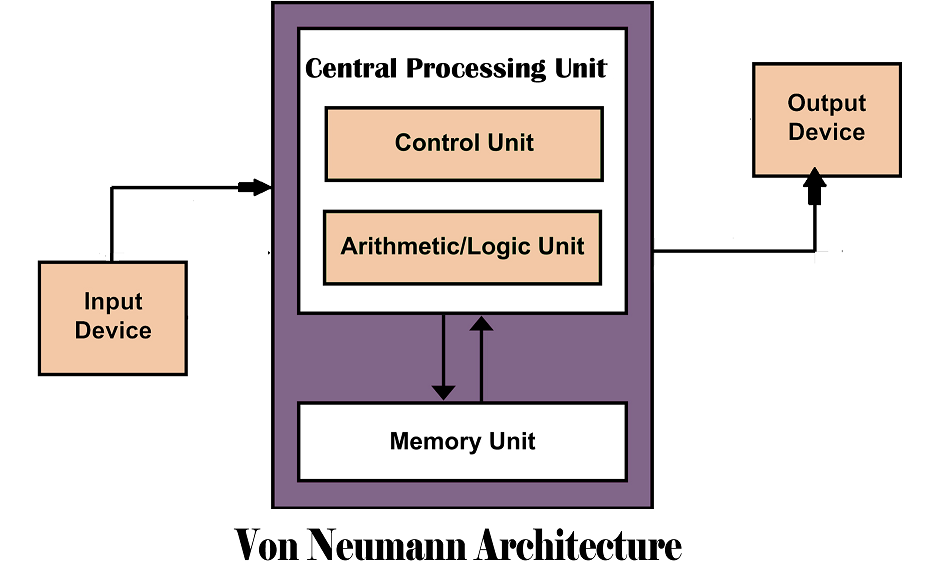
冯诺依曼架构的计算机拥有如下几个部分:
- memory,指令和数据都存在这里面
- control unit,用于从 memory 当中 fetch 指令
- arithmetic processor,用于执行指令
- bus,用于在 memory 和 cpu 之间传输数据。注意,memory 和 CPU 之间只有一条 data bus。因此,fetch 指令和操作 data,不能同时进行。注意从 memory 里面拿数据也是走 data bus 的,寻址猜是 memory bus。
- IO devices,也是用来传输数据的
除了冯诺依曼结构,还有一个叫做 哈佛结构(Harvard) 的东西,把指令和数据分开存储、分开传输。于是在哈佛结构的计算机上,fetch 指令和操作 data 就可以同时进行了。
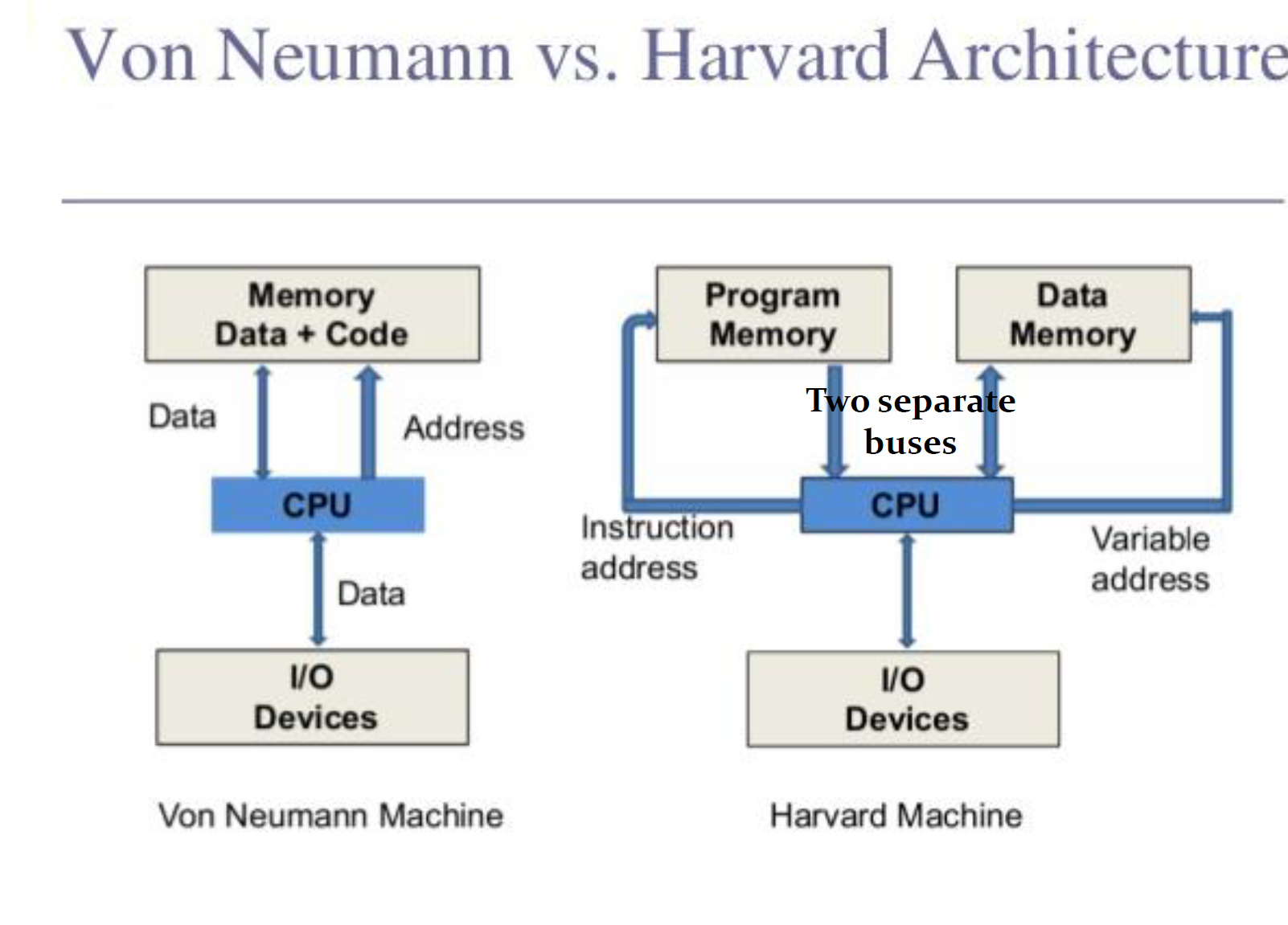
还有一种魔改版的哈佛架构,性能更好了一些。就是说指令和数据在同一块内存当中,但是不在同一块缓存当中,如图所示。

内存等级
内存分为不同等级,不同等级内存的制造技术、代价、容量、性能等都有差异。
这个金字塔从上往下,基本上就是速度越来越慢,单价越来越抵,容量越来越大。
整体来说:寄存器 > 缓存 > 物理内存 > 固态存储 > 硬盘虚拟内存。

寄存器、缓存、物理内存,访问时间都是纳秒级别的。但访问硬盘(尤其是机械硬盘)上的数据就是毫秒级别的。需要先通过文件系统读取、然后载入到内存、然后 CPU 才能看到。也就是说有一个明显的断层:

缓存和物理内存之间如何对应,是由硬件来决定的,而不是软件。操作系统管理的仅仅是内存和 Secondary Storage Swap Space。
内存管理,主要是关于 DRAM 部分的。memory manager 会检测哪里的内存是暂未被占用的,那么这里的内存就可以被 allocate 给某个进程。也会检测哪里的内存是已经作废了的,那么这里的内存就会被 deallocate 回收。
memory manager 也负责虚拟内存的管理,决定何时进行交换等。
内存管理
早期的计算机,或者说嵌入式系统,基本上都是 monoprogramming,即同一时间只有一个进程在运行,也就是说后台进程什么的都不存在。但是这样就会导致设备利用率很低(device usage)。现在一般没有 monoprogramming 了。
现在一般都是 multi-tasking 或者 multi-user system 了。但是这就让内存管理变难喽。
- 因为,进程 A 正在使用的内存,必须受到保护,不能被进程 B 给访问了。有点互斥的感觉。
- 第二个原因在于,编译期无法确定程序运行所在的内存位置。实际程序运行的位置,可能会受到其他进程的影响。也就是说,程序的内存地址只能是个相对的数值。内存管理器必须将程序代码里面使用的相对地址,准确映射到实际地址。
由于,访问内存的速度性能挺重要,所以刚刚所描述的 protection 和 relocation 都是由硬件实现的。
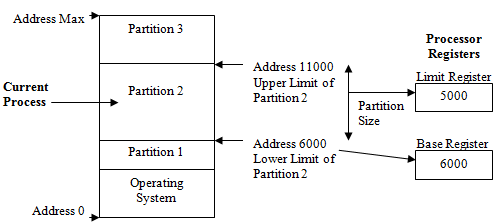
基地址寄存器和界限地址寄存器 base & limit
程序编译的时候,都是假设内存从位置 0 开始,范围 $[0, x)$。但是运行的时候不是零啊,咋整呢?
操作系统会在运行的时候把所有地址,从相对的转换成真实的。转换很简单,就是加上一个值:基地址 base。于是,实际地址变成了 $[\text{base}, x + \text{base})$。
但是 $x$ 取值太大会不会让这个进程跳到别的进程的内存里面去?于是还需要一个界限地址 limit。一个进程可以访问到的内存范围是 $[\text{base}, \text{base}+\text{limit})$。如果尝试访问这个区间以外的内存,那可能就会触发一个异常。
如图,base 5000,limit 6000,那么实际能访问的就是 $[5000, 11000)$。
分区问题
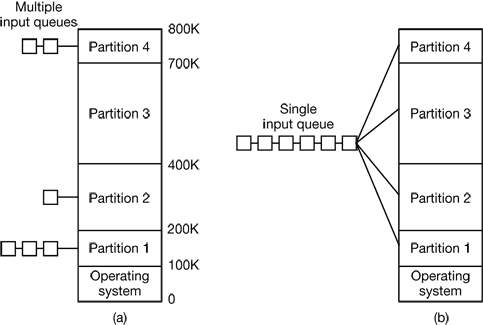
根据前面所述,每一个分区(对应着一对儿 base 与 limit)只能容纳一个进程。
不同的内存区域,大小也不尽相同。如果占用空间小的进程放到了一个很大的分区里面,那就太浪费了。但是假如小分区排队的进程太挤了,大分区是空的,那么也可以临时去大分区。就像核酸检测学生走教职工通道一样。所以那么应当把一个进程放到哪一个区域里面呢?
还是有两种方法:
- 为每一个分区设置一个队列(如图左)。队列里面放的是适合这个分区大小的进程。如果这个分区正在使用中,就必须等空闲之后再加载进程。
- 只用一个队列。每次把队首进程加载到第一个可以容纳他的分区里面去。(如图右)
除了把进程放到哪个分区里面,还得考虑,分区设多大?假如比较懒,每个分区都一样大,那么分区设几个?假如每个分区不一样大,普遍偏小了,然后来了一个进程,需要使用的内存比最大的一个分区还大,怎么办?那就得用 外部碎片(external fragmentation)。反过来,假如普遍偏大,那就会产生很多 内部碎片(internal fragmentation),而且还会影响整体的设备利用率。
紧缩 compaction

如图所示,可能是系统运行中内存分区的变化。
随着系统运行,free 的部分越来越少,越来越碎,产生了一大堆外部碎片。到最后每一个碎片都不能容纳一个进程。但是可能这些碎片的总空间,可以容纳一个进程。
通过 紧缩(compaction),就是移动内存的内容,把 free 的部分合并成一个。不过这个性能方面比较差,毕竟要复制内存内容,然后还要再改 base 寄存器。
所以 compaction 算法都要尽量减少复制的次数,以提升性能。
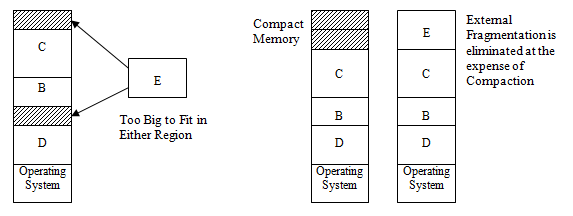
顺带一提,compaction 要求 relocation 过程必须是动态的,不能是静态的。也就是说,只需要修改 base 就可以实现移动内存。