Lecture 20. Normalization in Databases 数据库标准化
我们看到的绝大多数数据,都是 unnormalized 的。比如 word 里的数据、excel 里的数据之类的。
normalization 就是指 moving data into related tables 的过程。
关于怎么设计表格。理论上不难,但是纯理论,非常重要。
标准化数据表,有以下功效:
- save typing repetitive data 也就是减少重复数据
- 增加询问、排序等操作的灵活性(increase flexibility)
- 避免频繁的表重构(比如修改列)等(avoid frequent restructuring)
- 减少硬盘空间占用(与第一条相关)
例子
一,重复数据太多
比如这个表,有一大堆的重复数据:
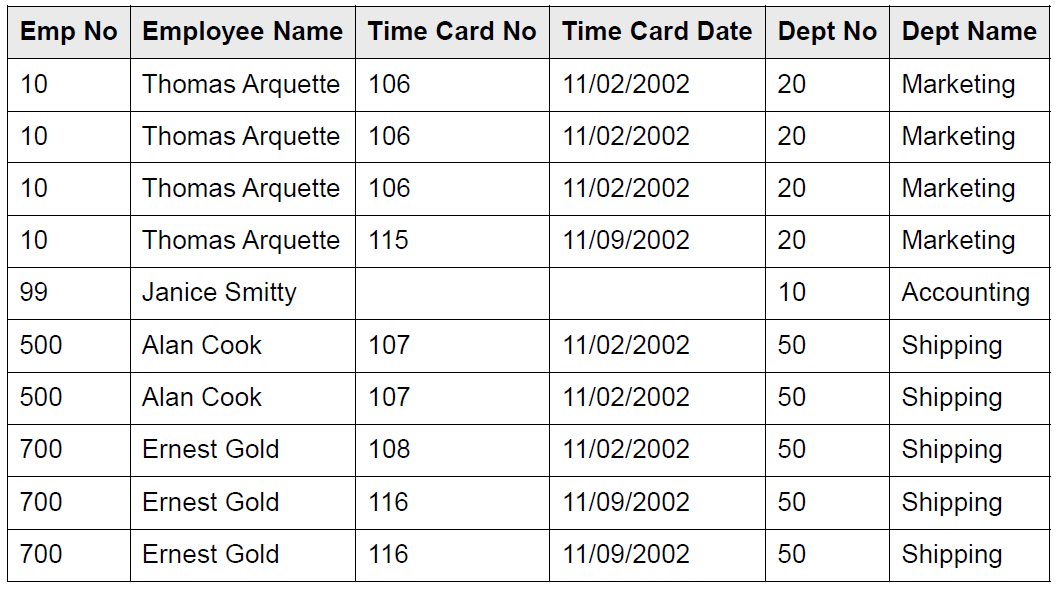
为了避免重复,不妨把这个大的表,拆分成三个小的表,然后这三个表通过主键(外键)联系起来:

二,行列结构不好
假如要插入一年的数据,那么所有行都会改变,这不好。
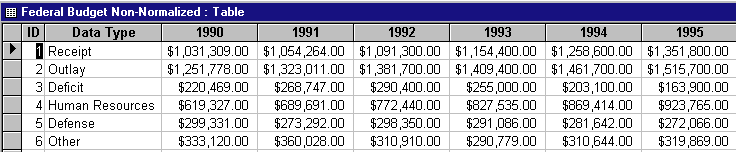
数据库希望插入新数据(年)只影响一行,所以建议改成这样:
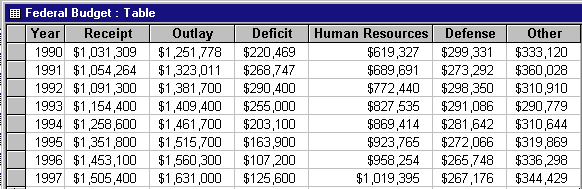
标准化种类
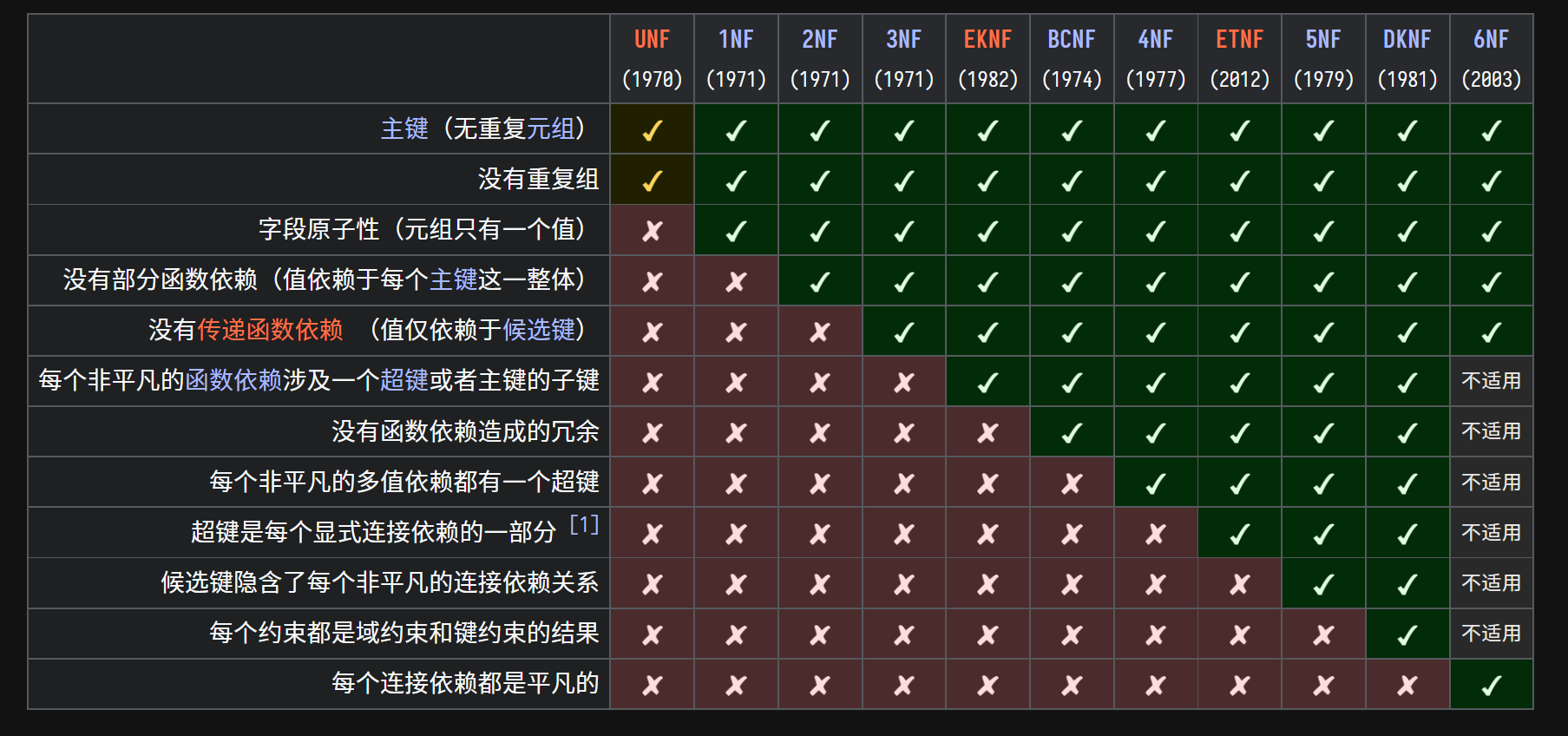
First normal form(一阶范式)
- 每个 field 只包含最小单位的有意义的值。比如,姓名拆成姓和名。
- 表不包含重复的 groups of fields,同一个 field 不包含重复的数据
对于第一个条件(每个列不能包含多个值),可以这样修改(上表不满足条件,下表满足)

但是虽然下面那张表满足了第一个条件,仍然不满足第二个条件。比如如果新增了一个 WH E,所有的行都要发生改动。相当于,repeating fields. 所以应该进一步改成这样:

但是主键也要修改。之前的主键是 PART 一个属性,现在的主键是 (Part, WH) 二元组。
Second normal form(二阶范式)
二阶范式,是一阶的加强版。
- usually used in tables with a multiple-fieled primary key(composite key)
- 每一个 non-key field 都跟整个主键有关系
- 每一个与主键无关的东西,都放在别的表里面
主要就是,用多个表,消除表当中的冗余数据(redundant data)
像这个表,不满足二阶范式。
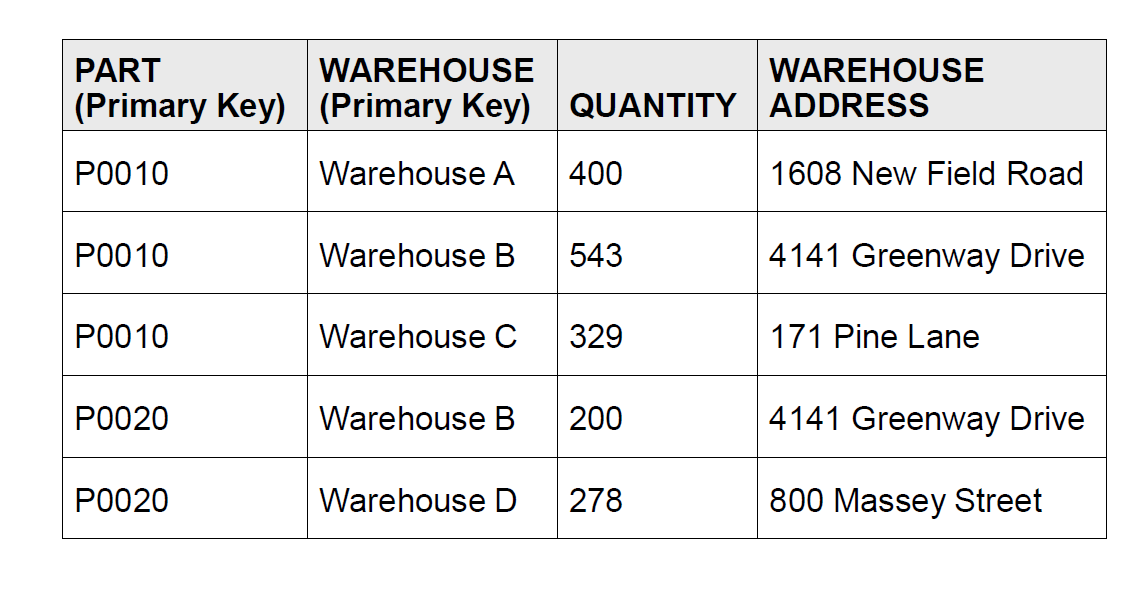
发现 WH B 出现了两次,且对应的地址(address)相等。这就意味着表格出现了冗余数据,要拆表。所有的 WH 只要编号相同,地址应当也是相同的。所以可以把地址拆出去,用 WH 作为主键连接:
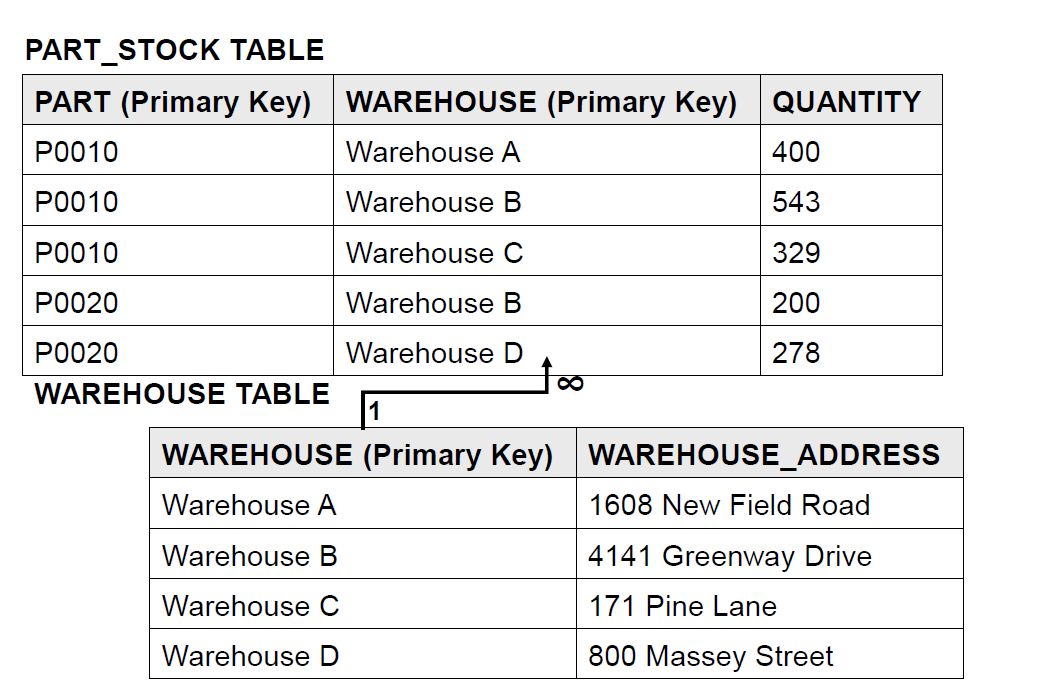
这样,就满足二阶范式了。
Third normal form(三阶范式)
三阶范式,仅考虑主键只有一列的表。
- 表当中,通常使用 single-field primary key
- 记录 do not depend on anything other than 主键
- 每一个 non-key field is a fact about the key
来看一个不满足三阶范式的例子

在这个表当中,DeptName 跟主键 EmpNo 好像没啥关系,只跟 WorkDept 有关。所以 DeptName 应该拆到别的表当中去。
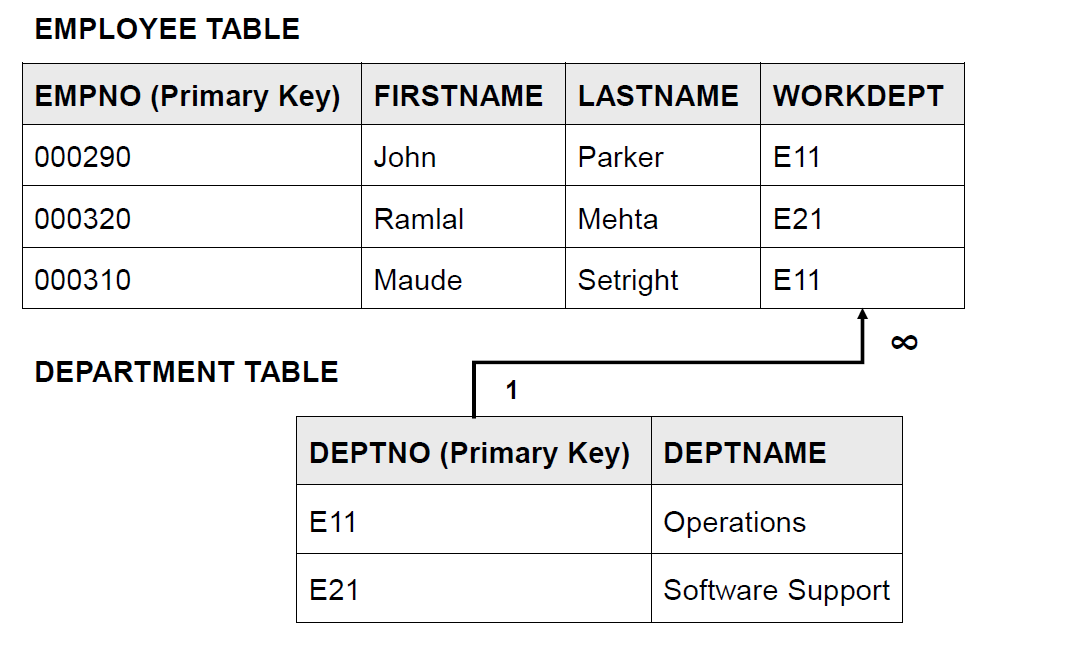
改成这样就满足三阶范式了。
其他例子
例一
关于学生和导师。
这个表,起初,连一阶范式都不满足。
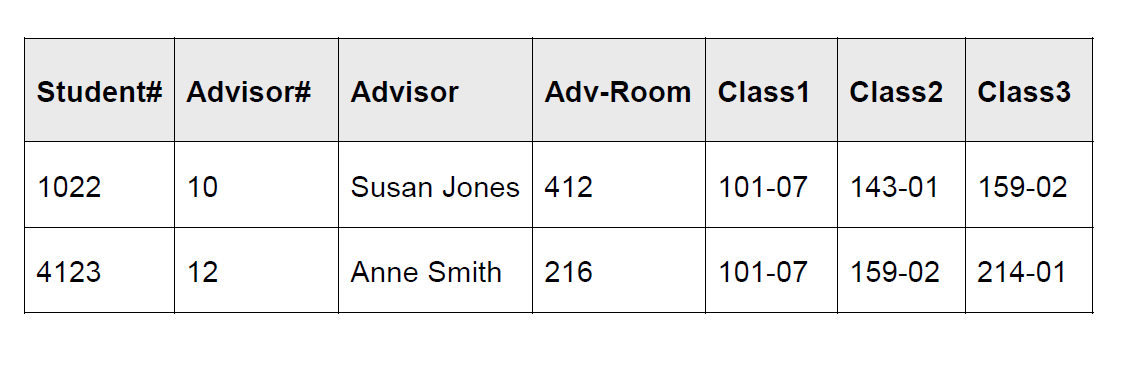
首先,姓名可以拆成两部分。其次,如果有新增第四间教室,所有的行都要改变,这不好。要让他满足一阶范式,就要没有重复的 fields(教室改成行而不是列,用三行表示三个不同的教室),而且 data in smallest parts(姓名拆开):
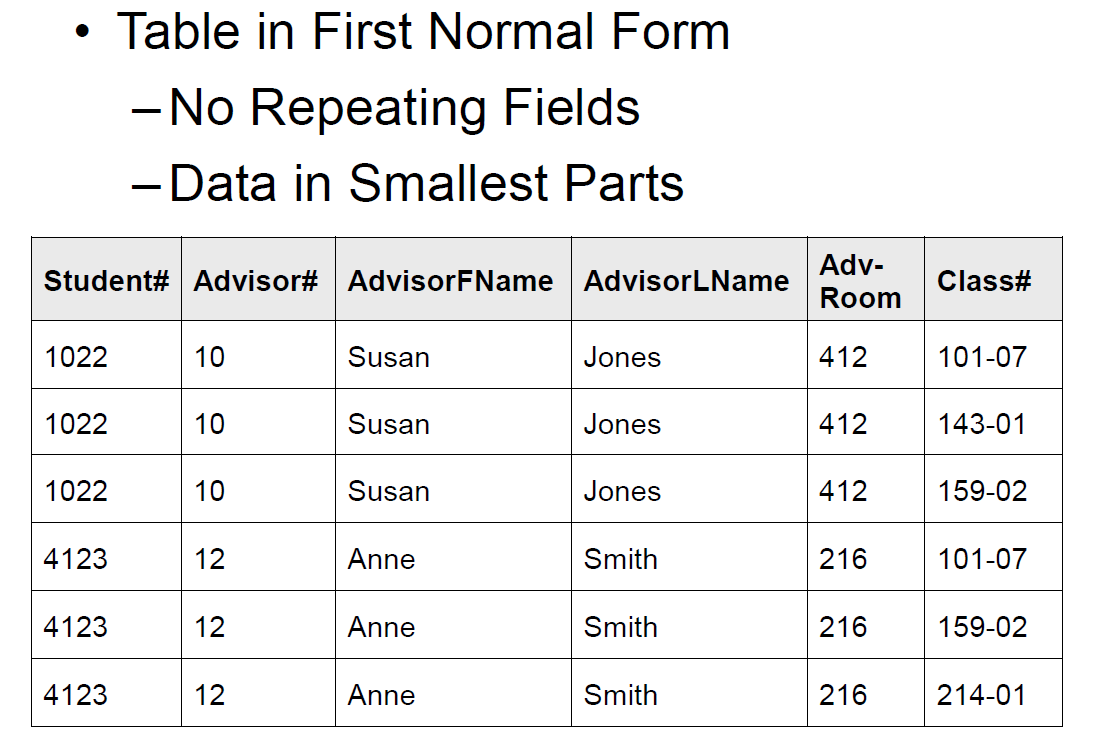
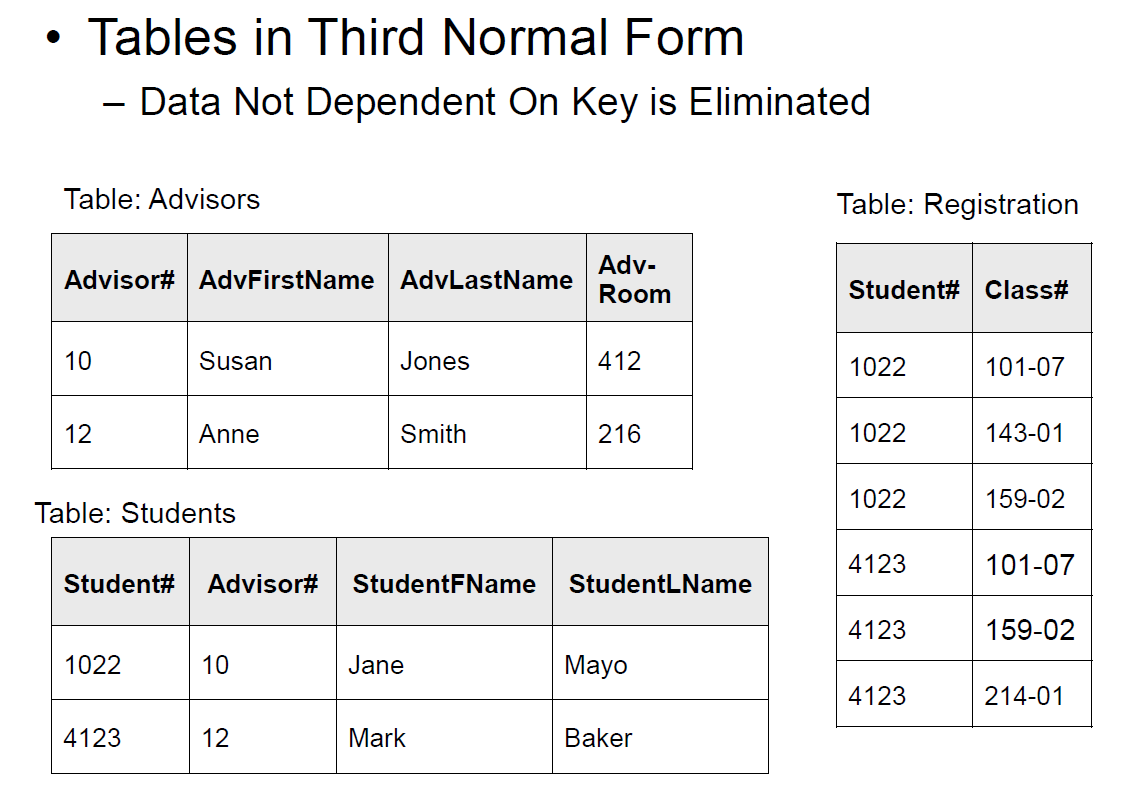
这样虽然不存在 repeated fields 了,但是仍然存在 redundant data,不满足二阶范式。回忆:二阶范式考虑多个列作为主键的情况。对于多列主键 (学生,导师,教室),分析所有不是主键的列。发现,所有的非主键的列,都只跟三个主键当中的其中一列有关。所以这就不满足二阶范式了。于是,导师的四列,可以拆到单独的表格里面去。

但是还不满足三阶范式。回忆:三阶范式考虑单主键的情况。显然,导师的姓名和办公室,跟主键 student id 没啥关系。所以导师的信息可以拆出去。
例二
关于员工、部门、项目的一个数据库。
起初设计了一个不符合一阶范式的表。
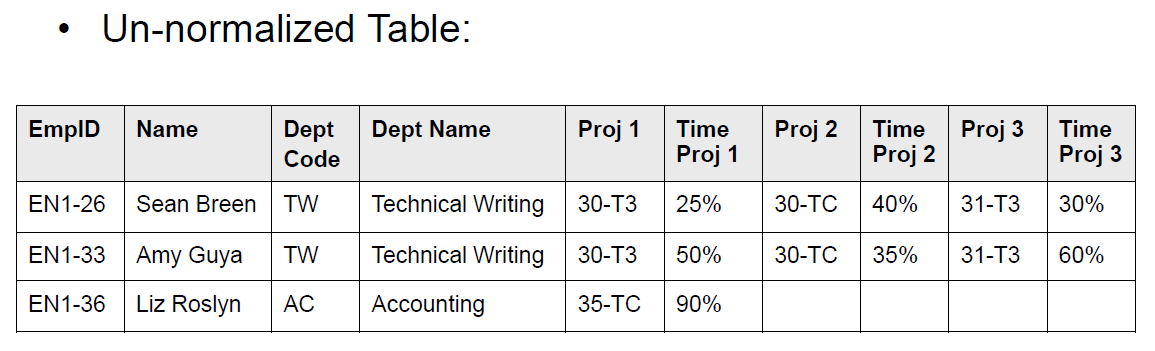
不符合是因为,人的姓名可以拆,而且 proj/time 123 重复了。修改如下,满足第一范式:
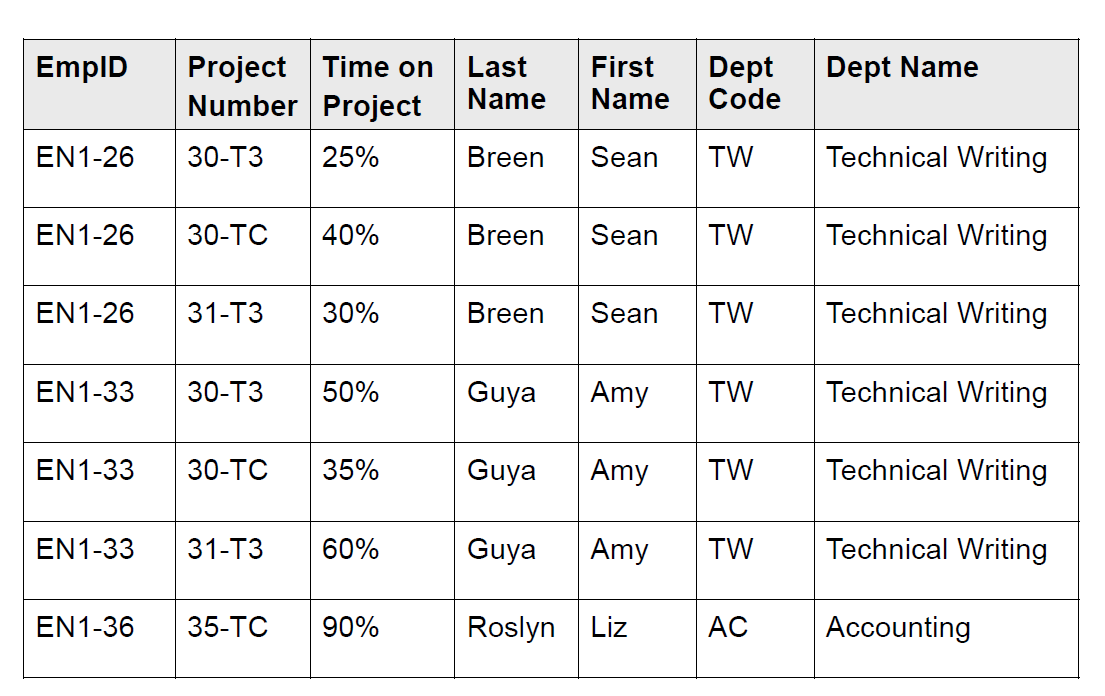
然后考虑是否满足二阶范式?二阶范式要考虑多主键。这个表的主键应该是 (empId, projId),但是其中 empId 可以单独决定姓名、部门等信息,所以要把姓名、部门之类的单独拆出去。
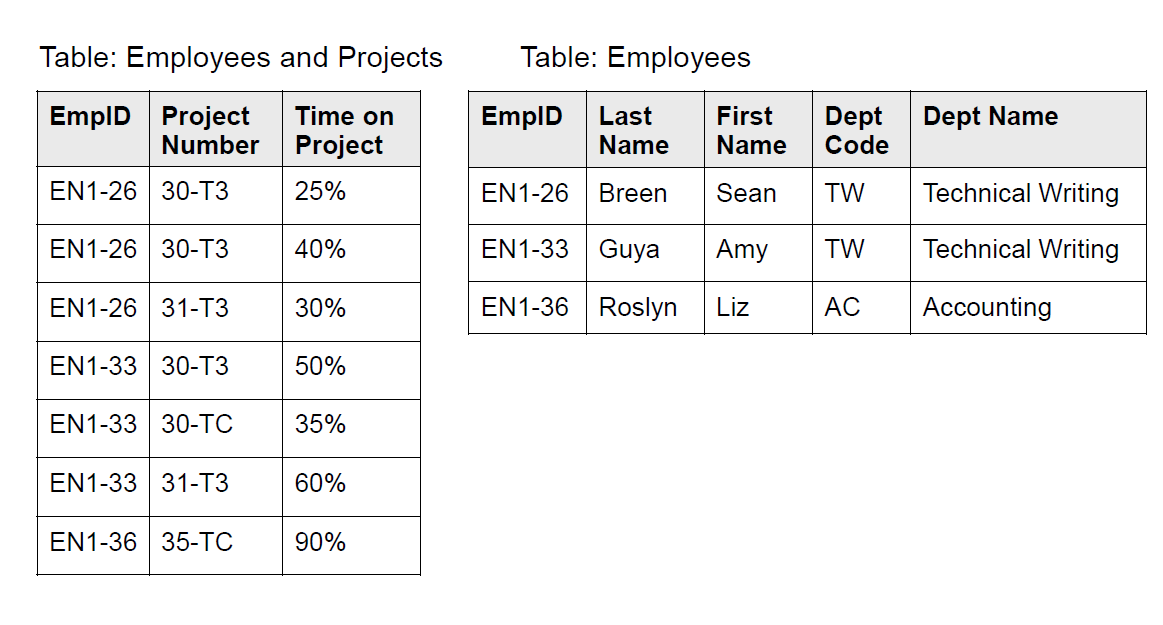
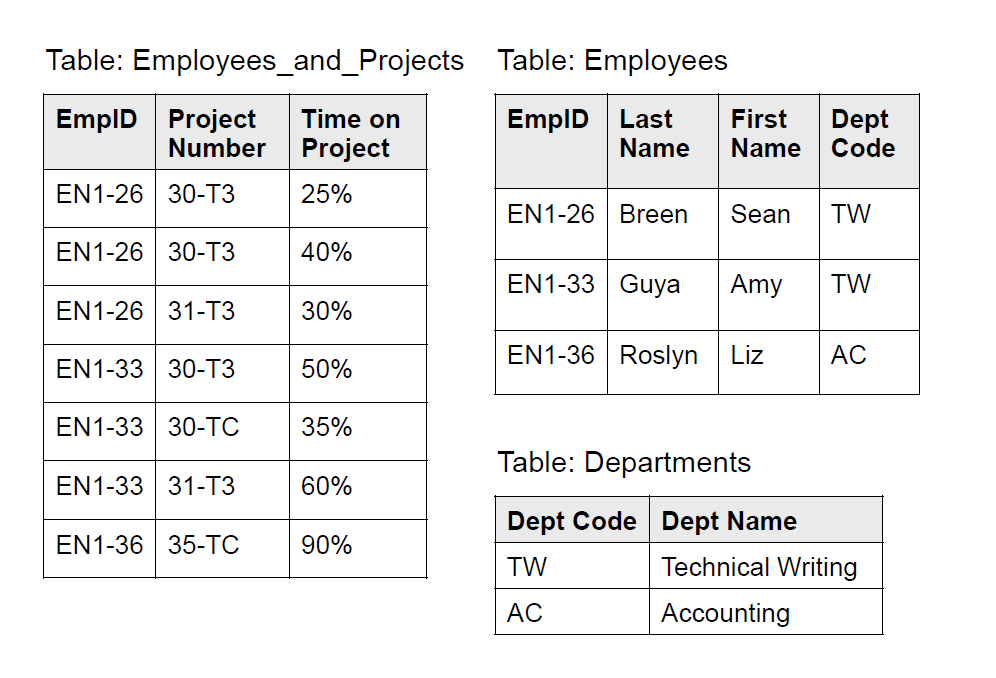
上面这样的设计,满足 2NF 了。但是 deptName 是跟 deptId 有关的。这里不满足第三范式,所以也要拆出去(否则如果新增一个 TW 部门的员工,还有额外标注一下 deptName,冗余了)
例三
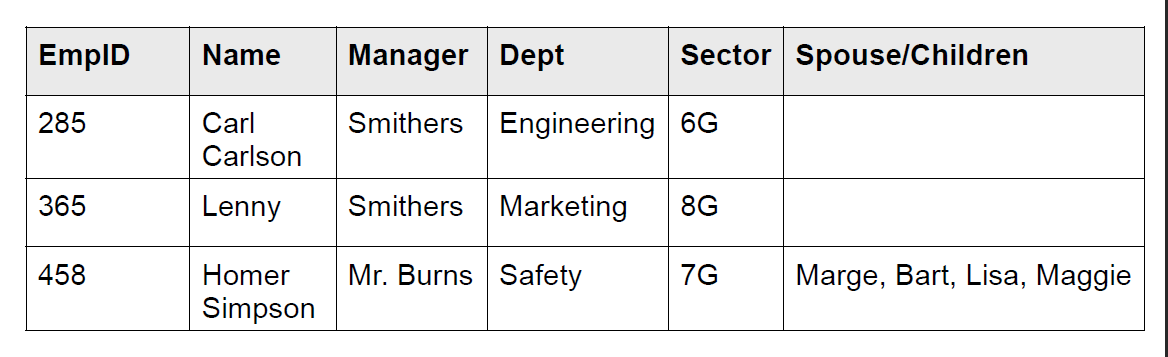
可以看到最后一列不满足第一范式。应当拆成四列,再转行:

现在满足 1NF 了。观察发现,主键是 (empID, dependent) 二元组。由于姓名、经理、部门、领域等信息,仅与二元组之中 empid 有关,所以这些要拆出去。
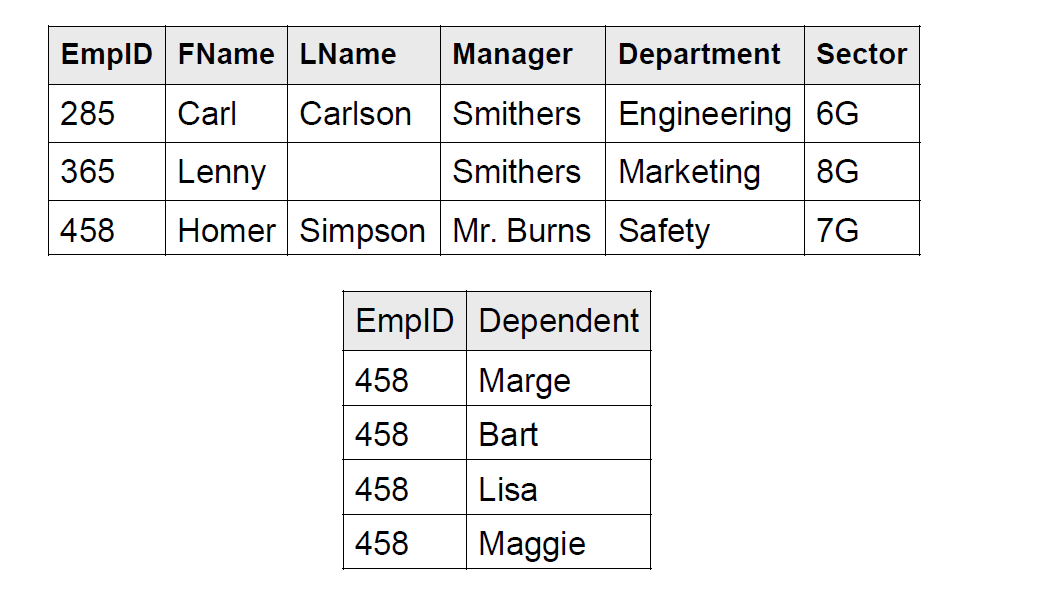
这样就满足 2NF 了。不过由于 Manager 的名字比较长,可以优化一下,假如 ManagerID 信息。
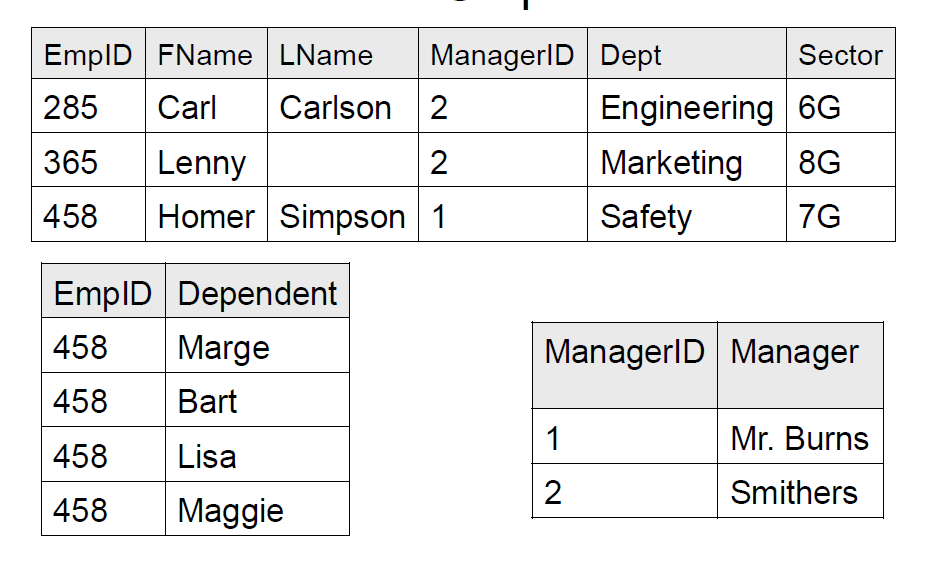
现在来分析一下第三范式。由于员工决定部门,而部门决定经理和研究领域,所以 ManagerID 和 Sector 也可以拆出去。同时,Dept 太长了,也可以起一个简称来简化数据库。
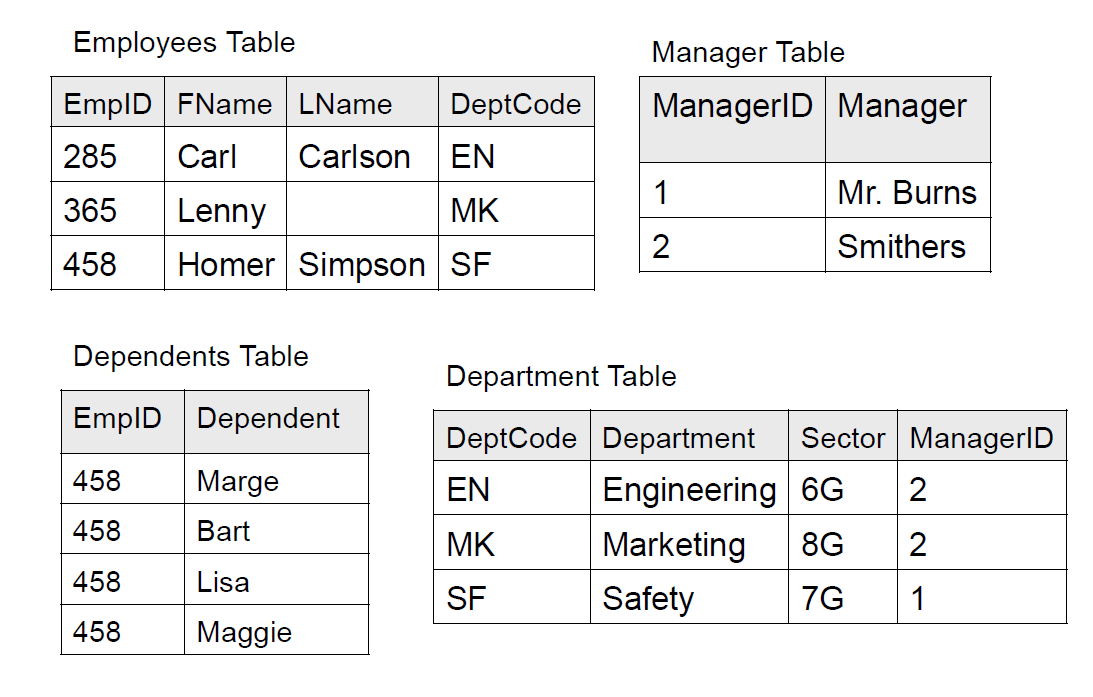
这样就满足 3NF 了。
例四例五
ppt 77~81.