Lecture 11-12. Table Aliases, Working with Functions in SQL and PostgreSQL 表别名、函数
GROUP BY 和 ORDER BY 关键字
示例:
作用是,把所有属性值相同的行放在一起,再按照这个值排序,统计每个属性有多少行:
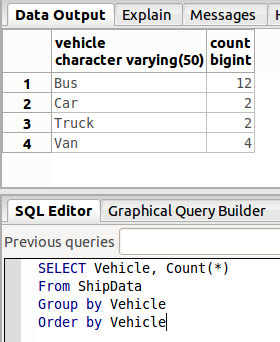
也可以捆绑两个甚至更多的属性值。比如:
SELECT <colName1>, <colName2>, COUNT(*) FROM <tableName> GROUP BY <colName1>, <colName2> ORDER BY <colName1>, <colName2>;
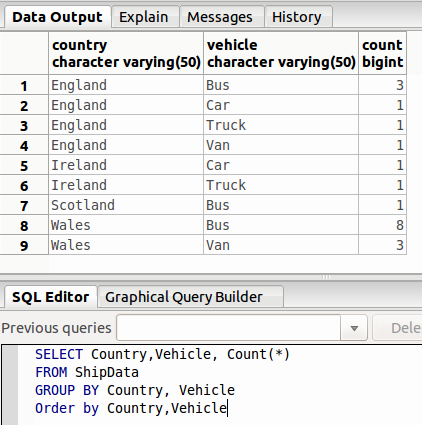
然而,GROUP BY 和 ORDER BY 里面的东西,必须保证在 SELECT 里面有出现过。
列别名
在一个 SQL 语句当中,可以临时的对表或者列进行改名,但是到下一条语句里面,这个名字就失效了。
有时候原名太长,想要简写。就像 Python 当中,有人喜欢把 numpy 简写成 npy,这种别名可以让代码更简洁。也有时候原名太短,不知道写的啥,就换一个更加清晰的名字。~~比如有人打 ACM 喜欢用变量 abcdefg,不如 cnt, pos 之类的望文生义的变量名。~~
在数据库中,还有一种额外的功效,就是对原名起到保密作用,比如把 Password 改名成一个不太敏感的名字之类的。
示例:
/* 给列 rrp 取别名 Recommended Price */
SELECT rrp as "Recommended Price" from <tableName> ORDER BY rrp DESC;
SELECT rrp as "Recommended Price" from <tableName> ORDER BY "Recommended Price" DESC;
注意,这里需要双引号!字符串、时间戳啥的都是单引号,这里是第一次遇到双引号!
这里可能还感觉不到。但是将来学到 JOIN 关键字之后,别名的重要性就凸显出来了。
表别名
观察发现,这里的表别名没有引号,因此,这时候的命名方式就像变量名一样。如果想要让别名包含空格,那就得弄成字符串的形式,双引号。
函数
函数分为两类,aggregate 函数和 operational 函数。aggregate 函数的参数有多个,operational 函数只有一个参数。
有时候 operational 函数是传引用的,可以改变输入参数的值。但是 aggregate 函数不能改变参数的值。
此外,aggregate 函数必须要配合 GROUP BY(否则报错),故通常用于 SELECT 语句。而 operational 语句在 SELECT 和 WHERE 当中都比较常用。
在本节课开头提到的 COUNT() 函数就是一个 aggregate 函数。然而经常通过 COUNT(*) 的形式传入所有的,对所有的行进行计数。
还有,aggregate 函数计算的时候,会忽略掉 NULL 值。所以说,COUNT() 的计数结果,不会包含值是 NULL 的那些。
aggregate 函数举例
MIN()MAX()AVG()SUM()STDDEV()
示例:
SQL 的输出会新建一个列,名字是函数名,或者指定的显示名。
更加复杂的一个例子:(显示每个组的 sum。)
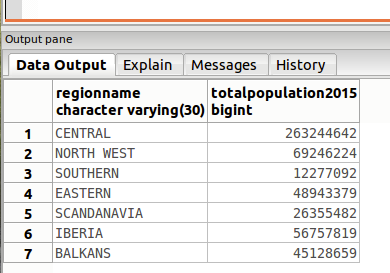
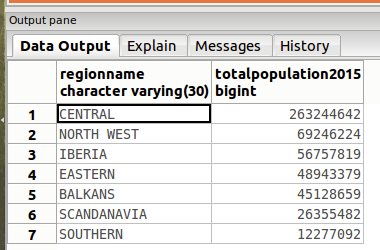
再复杂一点的一个例子(输出结果按照 sum 的值进行排序):
SELECT Region as RegionName, SUM(Pop2015) as TotalPopulation2015
FROM PopulationEU
GROUP BY Region /* 这里不一定是函数传进去的列 */
ORDER BY TotalPopulation2015 desc;
多表查询
当查询的两个表当中存在同名的列,在 SELECT 里面就必须要说清楚是哪个表当中的列。如果表名字比较长,用别名就会方便一些了~
SELECT A1.Appname, A2.Appname, A2.usability, A1.usability
FROM AliasExample AS A1, AliasExample2 AS A2
WHERE A1.usability = A2.usability
但是这样的话,输出结果会显示两个列都叫 Appname。为了区分,最好给这两个列也 AS一个别名:
SELECT A1.Appname AS "A1 Apps", A2.Appname AS "A2 Apps",
A2.usability AS "A2 Usability", A1.usability AS "A1 Usability"
FROM AliasExample AS A1, AliasExample2 AS A2
WHERE A1.usability = A2.usability
笛卡尔连接 Cartesian Join
(A, B) 与 (1, 2, 3) 的连接是:(A, 1),(A, 2),(A, 3),(B, 1),(B, 2),(B, 3)。~~这跟笛卡尔积有啥区别?~~
如果表一有 20 行,表二有 40 行,那么笛卡尔连接就有 800 行。太多了!所以通常都用 WHERE 来加一点限制。这时候的笛卡尔连接,就是原本笛卡尔积的一个子集了~
多语句查询
就是有些问题需要写不止一条 SQL。然后对于多个语句的输出结果,手动结合一下,获得最终答案。比如:第一条语句问 X 有多少,第二条问 Y 有多少。然后手算 X 占 Y 的百分之多少之类的。