Lecture 8 系统设计
https://zh.wikipedia.org/zh-cn/%E6%8E%A5%E5%8F%A3%E9%9A%94%E7%A6%BB%E5%8E%9F%E5%88%99
概念:OOP、OOD、OOA
OOP:面向对象编程
程序是若干个对象构成的。程序的基本元素是对象,而不是算法。
对象是类的实例。
OOD:面向对象设计
OOD 是一种 method。
OOD 的意思差不多就是用类和对象把程序的结构表达出来。
所以 OOD 的成果是蓝图(blueprint)而不是程序。
OOA:面向对象分析
传统的分析方式,比如数据流图,专注于数据的流动;而面向对象分析,专注于对真实世界进行建模,得到一组对象模型。
一般要先有了 OOA,才能进行 OOD 的步骤。在分析和设计的早期阶段,要先确定好,有哪些类;然后,根据需求,创建一个对象模型。
OOA 有如下几种常见的方法:
- Use case 分析
- Classical 分析
- Behavior 分析
- CRC 卡分析(Class-Responsibilities-Collaboration)
也有两种结构分析方式:
- 数据流图(data flow)
- ER 图(Entity-relationship)
非结构化的分析方法
Textual / UserCase 分析
就是从文字描述或者 Usecase Diagram 里面,找出可能的对象、属性、操作、关系等信息。对于文字信息,主要就是主谓宾。
找到之后标注出来。如图。

但是通过这种方式只能产出比较低级、不完整的类结构。因此还需要再结合其他方法完善一下。
Classical 分析
大概意思就是根据实际生活经验进行分析。比如,对于职员管理系统,User 类就可以包含 Manager,Stuff 等子类。这些东西可能在文字的需求描述中没体现出来,但是根据实际生活经验,是要有的。
Behavior 分析
大概意思就是,根据已有的这些类和对象的可能产生的行为,把具有相似行为的类划分到一个组里面。
这样就方便把不同的任务分配给不同的组,而且也方便研究哪个行为是哪个组发出的。
如果有一个组发出了一个重要的行为,那这个组就要视作一个类。
CRC 卡分析
CRC 卡(Class Responsibility Collaborator)
CRC 卡顾名思义,用来描述一个类的职责和合作关系。
- 职责,基本上就相当于对象的行为。在分析和设计阶段,要确定好每一个类的对象有哪些职责。但它并不等于方法。因为可能好多个方法才能组合起来完成一个职责。此外,职责也有两种不同的类型,有的职责是要计算某个东西,有的职责只是要接收某个东西。
- 一堆类假如合起来能够支持功能需求,那么这就够构成了 collaboration 关系。
CRC 卡当中可以包含很多信息。结合用例,可以发掘不少隐含的类、属性等。

用 CRC 卡进行分析的步骤
- 阅读 use case 的描述,挑一条最难理解的出来,应用其他几种分析方法,找出需要的类,然后为这些类建立 CRC 卡。
- 然后找出涉及到的相关的对象。然后团队中的队员,搞 role-play,分别饰演一个对象,相互提问:你知道哪些东西?你能做什么?根据这些,填写 CRC 卡片。
- 重复上述步骤,直到所有的 use case 都处理过了。
Data Flow Diagrams 数据流图(DFDs)
Data-flow diagrams (DFDs) are system models that show a functional perspective where each transformation represents a single function or process. DFDs are used to show how data flows through a sequence of processing steps. For example, a processing step could be the filtering of duplicate records in a customer database. The data is transformed at each step before moving on to the next stage. These processing steps or transformations represent software processes or functions, where data-flow diagrams are used to document a software design. Activity diagrams in the UML may be used to represent DFDs. SE10 第 154 页。 Data-flow diagrams can be represented in the UML using the activity diagram type. 第 155 页
有 3d 和 2d 两种画法。通常手画 2d,软件画的可以是 3d。
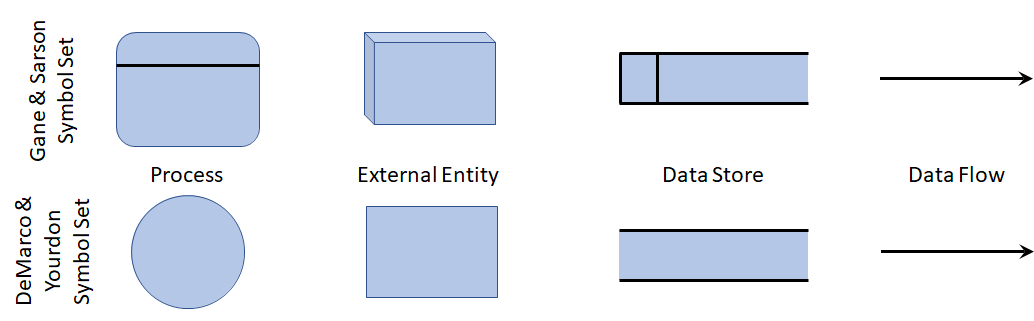
DFD 的成分
Process
Process 具有 input 和 output。
output 和 input 之间不一定有直接的关系。process 是一个黑箱,里面发生了啥都不知道,只能说 output 与 input 有间接的关系。
一般给 process 起名字的时候,要望文生义。比如起名「book ticket」这种动词加名词的形式,一看就知道,哦,要买票。
Data Flow
dataflow 描述了数据的流动方向。dataflow(箭头)可以表述好多数据。
给 dataflow 起名字的时候,一般都是名词的单数形式。
注意画图的时候不要出现以下情况:
- 一个 process 只有输出没有输入(Spontaneous generation)
- 一个 process 只有输入没有输出(black hole)
- 一个 process 有输入输出,但是输入不足以产生输出(gray hole,差不多就是计算 $x+y$ 但只知道 $x$)
Data Store
就是把数据存储下来,将来供别的 process 使用。
起名的时候,应当用名词的复数形式。课件里面写的 ticket,错了,要改成 tickets。
两个 datastore 之间不应直接相连。中间应当经过别的 process 处理。
External Entity
外部实体给进程提供输入数据(source),也可以从进程接收输出数据(sink),但是 EE 和 EE 之间不能直接交换数据,中间至少要经过某个 process。EE 也不能给 Data Store 发送数据。
有外部实体的地方,就可以当作系统的边界(boundary)。
起名字要使用单数形式。
画 DFD 的步骤
1. context diagram
先搞一个 context diagram 出来。这是最顶级的视图,描述了系统的边界。
- 只有一个进程,编号 0
- 有若干实体,也有 dataflow
- 不存在 data store

2. diagram 0
是一个高层的 overview,记作 diagram-0,可以看到系统当中的主要组件。
- 这一层级当中可以出现 data store
- 注意进程的编号并不代表进程被执行的次序
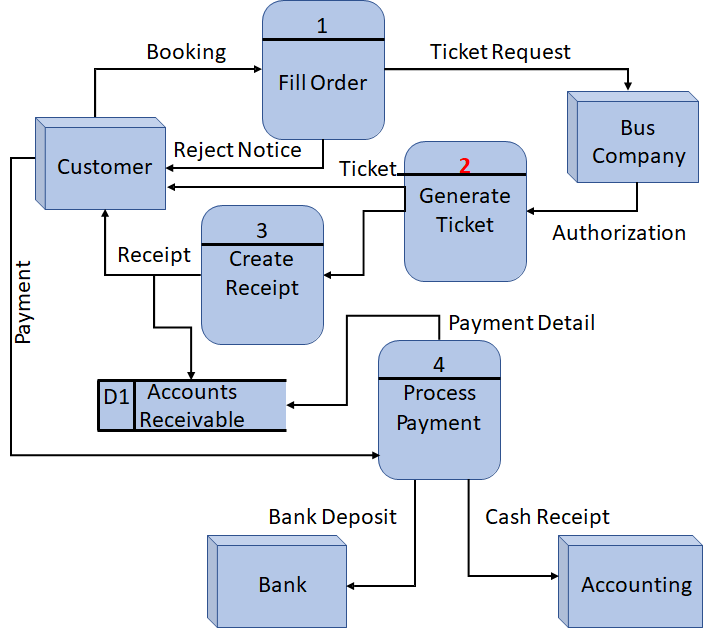
3. low level DFDs
就是 level-1,level-2,…
在确定低级功能之前,底层的图是没法画的。
所有低一等级的 DFD 都是基于上一等级的细化。
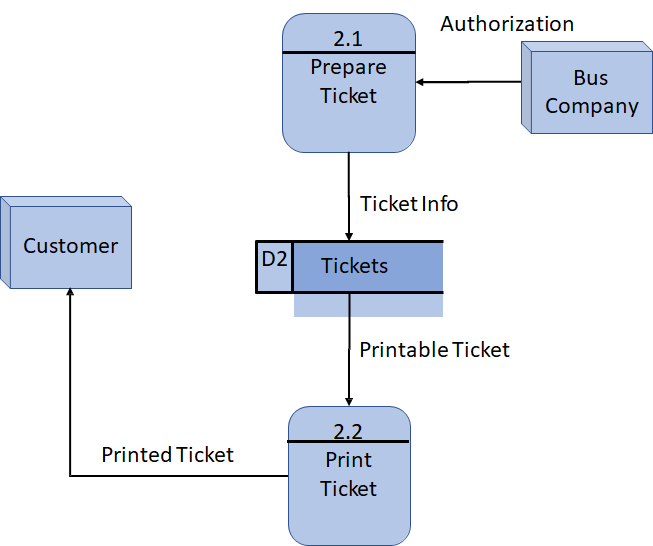
另一个 DFD 的示意图
context diagram 等级

level-0 等级

level-1 等级(进程 4 的细化)
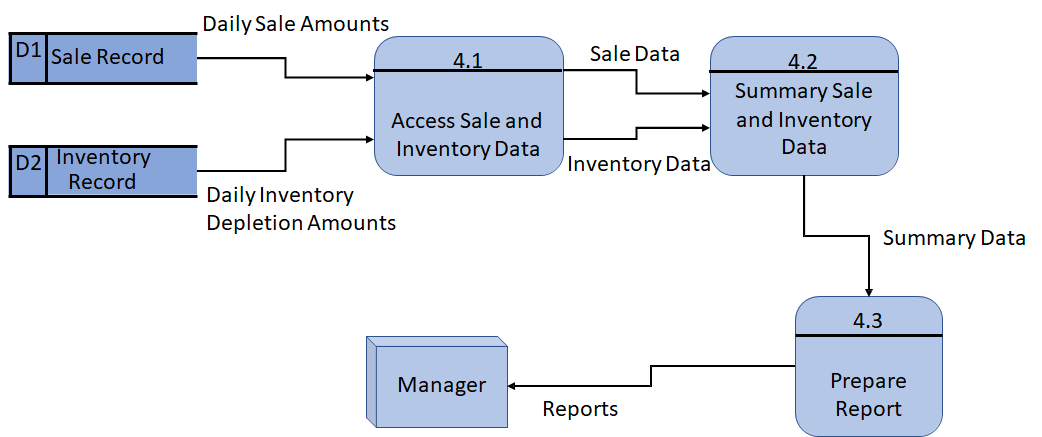
level-2 等级(进程 4.3 的细化)
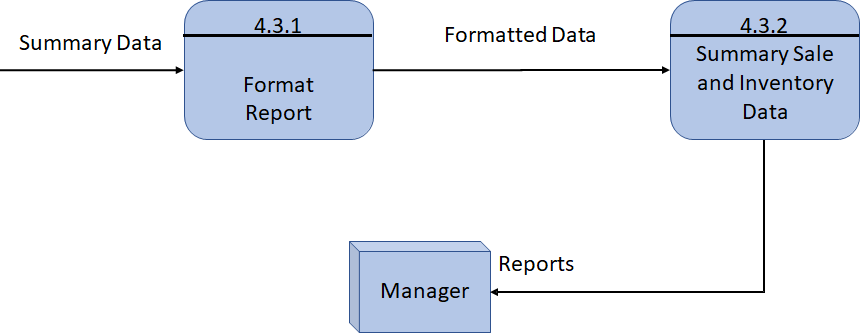
DFD 小结
- DFD 用于对数据和进程进行建模,可以看到数据的传递方向
- DFD 也可以体现整个系统的层级
- 完整的 DFD 应该细化到 primitive 等级,即所有的组件都不能再细化
ER 图
概念数据模型
概念数据模型(conceptual data modelling) 是一种能够独立于任何 DBMS 的,捕获、组织数据的详细的模型。
模型当中,包含了数据的定义、结构,以及关系,但是不像 DFD 那样关注数据的传递和使用。
由于数据的特征在数据库设计、程序设计、显示格式等方面都非常重要,所以概念数据模型在这个方面很有用。
数据建模可以是自顶向下的也可以是自底向上的。
- 自顶向下就是通过 interview 等手段,问出包含哪些 entity 和 relationship
- 自底向上就是通过文档或票据等文件,推出有哪些 entity 和 relationship
ER 图
ER 模型表示数据逻辑,在数据库系统当中非常常用,而 ER 图是 ER 模型的图形化表示。ER 图是最常用的描述概念数据模型的图表手段。
在 ER 模型当中,主要包含数据实体、关系以及属性。其中实体应当是单数名词形式。
实体
实体又分为 strong entity(parent entity)、weak entity、associative entity:
- 强实体用单方框,必须拥有主键,与其他实体是独立的
- 弱实体是双方框,没有主键,要结合 parent entity 才有意义
- associative entity 是圆角方框,类似数据库的关系表

属性
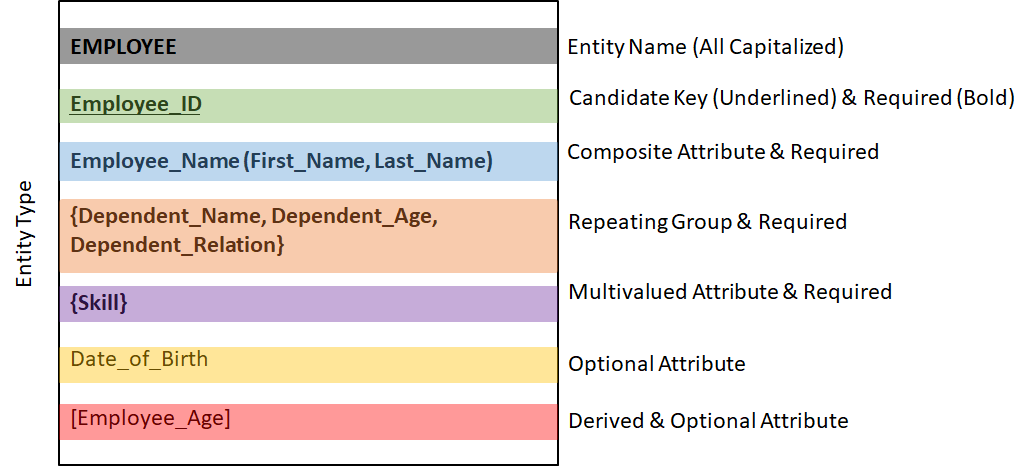
每个实体都拥有若干个属性(列)。相同类型的实体实例(行)之间,用候选键(candidate key)进行区分。一个属性也可以包含多个值。也有的属性可有可无,叫做 optional attribute。可有可无的属性可能是通过别的属性计算出来的(derived)。
下图描述了不同类型的属性的命名格式。实体类型应当全部大写,候选键应当加下划线。粗体非粗体区分是否可选。详情如下。
关系
通常关系是动词短语来表示。
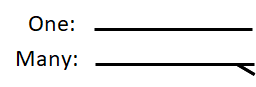
有一个叫做度(degree)的概念,跟图的度差不多,表示这个关系连接的实体的数量。一般都是一元关系、二元关系、三元关系(unary、binary、ternary)。其中一元关系也叫做递归关系。也有更高度数的,但是不常见。
几对几的关系
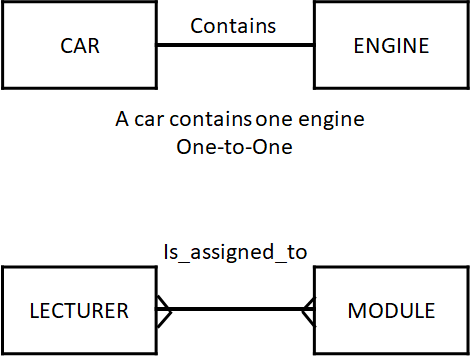
在 CS335 这门课的 ER 图当中,一元关系就是一条简单的线,多元关系就在线的端点出开叉:
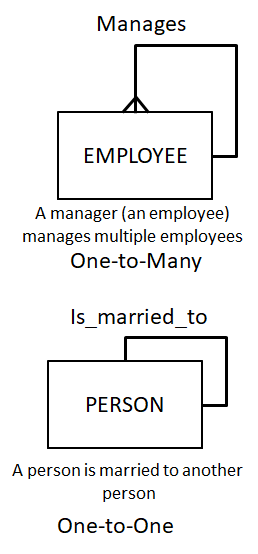
比如一个人可能管理多个人,而只能与一个人婚配,两个关系(都是人与人,所以是一元关系)分别是一对多、一对一,于是就可以这么画:
对于二元关系,也是类似。一对一就是简单的实线,多对多就是两端都开叉的实线。
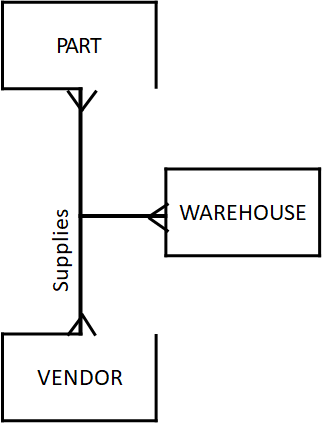
三元关系其实已经比较少了,下图是商品、供应商、仓库的三元关系,多对多对多:
更详细的几对几关系
额外的圆圈表示 optional,额外的竖线表示 must。
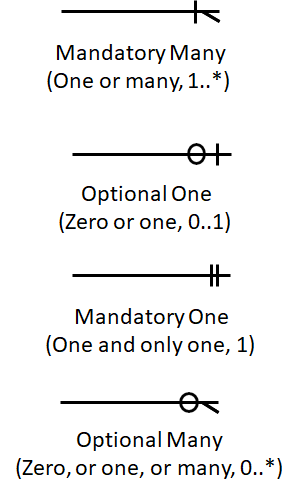
研究研究下面四个关系画法的含义,但是不要过于纠结这里的逻辑关系,老外的思维很怪。阅读的时候,文字描述看离的近的,符号看离得远的。

于是把这些东西整合起来就变成了这样子

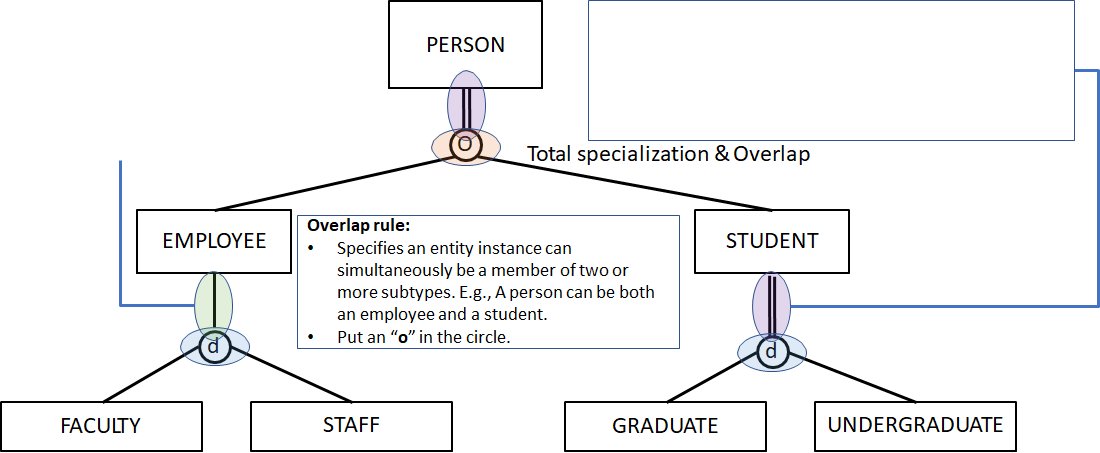
实体的 supertype 与 subtype
类似编程当中的父类和子类。一般画在上面的是 supertype,下面的额 subtype。比如下图表示,员工包含开发者和管理者两类:
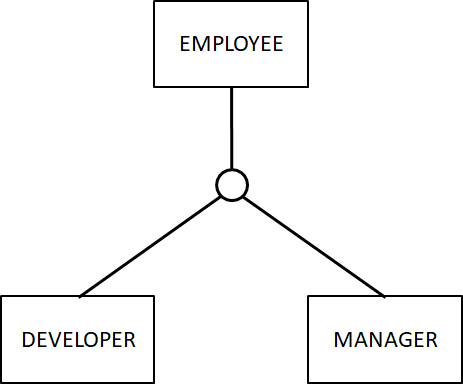
有时候图里画了两条线,有时候只画了一条线,这两种表示的含义不一样。
- 一条线表示 partial participation,意思是说,supertype 里面有一部分是这些 subtype,比如员工有的是普通职员,有的是管理人员,也有的是保安之类的
- 两条线表示 total participation,意思是说,subtype 是 supertype 的完整的集合划分,比如学生,只能分成已毕业和未毕业两类
- Total Participation − Each entity is involved in the relationship. Total participation is represented by double lines.
- Partial participation − Not all entities are involved in the relationship. Partial participation is represented by single lines.
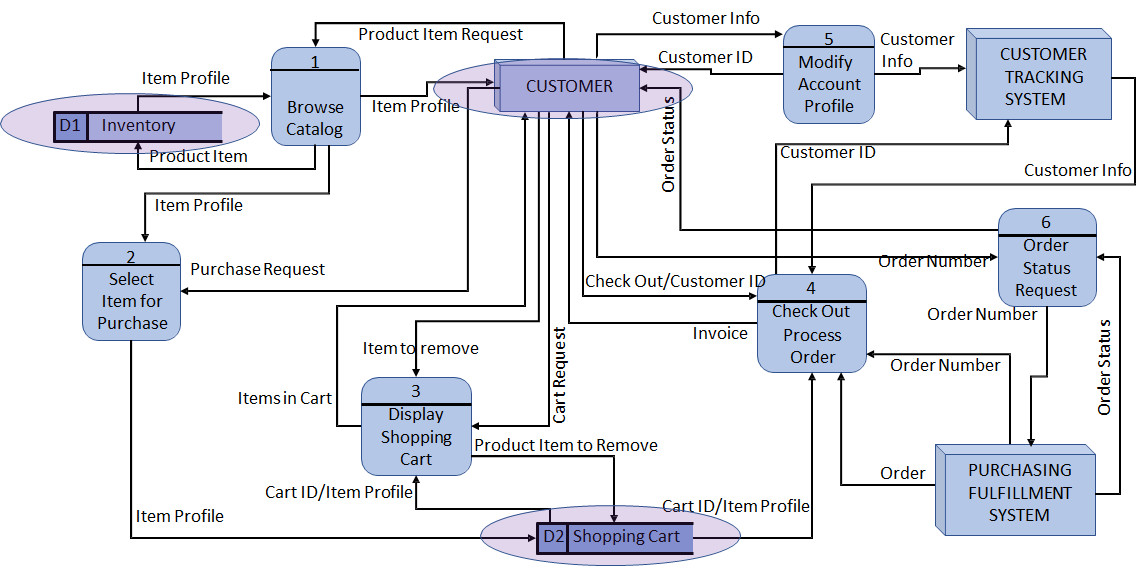
DFD 与 ERD 的结合
DFD 与 ERD 结合起来用更好。
如果在 DFD 里面添加 ERD 的思想,就把所有的 data store 标注上对应的什么 entity,说白了就是说清楚 data store 里面的数据是啥类型呗
OOA 小结
- Textual 分析,通常通过阅读 use case 等文字信息,找出潜在的类、对象、关系、属性、操作等
- Classical 分析,从日常生活经验总结类的结构
- Behavior 分析,就是把具有相似的行为的组到一起
- CRC 卡分析,关注类之间的 responsibilities 和 collaboration
- DFD 图可以展现数据的传递
- ER 图(概念数据模型)展现的是结构关系,不注重数据
面向对象设计
GRASP 原则:给对象赋予适当职责
GRASP 是 通用职责分配软件模式(General Responsibility Assignment Software Patterns) 的简称
GRASP 包含 9 条模式与原则:
- 控制器 controller
- 创建者 creator
- 中介 indirection
- 信息专家 information expert
- 低耦合性 low coupling
- 高内聚性 high cohesion
- 多态 polymorphism
- 保护变化 protect variations
- 纯虚构 pure fabrication

下面将会根据下图的例子(用户故事识别卡管理系统)来分析 GRASP

概念补充
领域模型 domain model
领域模型可以被看作是一个系统的概念模型,用于以可视化的形式描述系统中的各个实体及其之间的关系。
领域模型包含:
- 领域对象
- 概念类及其属性
- 概念类之间的关系
Domain Model == Conceptual Model == Domain Object Model == Analysis Object Model
UML 当中,Class Diagram 用来描述领域模型。
模型-视图分离原则 Model-View Separation
首先,UI 层与其他模块的可见性关系如何?
- 不要将非 UI 的对象直接与 UI 层相连,比如不要在
Project(UI 无关)当中创建 UI 对象的 ref - 也不要把应用程序的逻辑放在 UI 方法当中,比如不要在
JFrameWindow当中实现getUserStory()
第二,domain object 与 UI 有关的模块之间,应当如何通信?
- 使用观察者模式。domain object 会给 UI 模块发送消息。
遵循这个原则就可以让应用程序高度封装。UI 的就只负责 UI,domain object 负责处理逻辑和数据等。
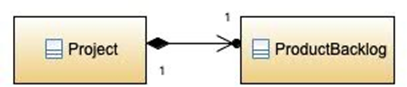
1. 创建者 creator
问题:哪个类别要创建物件 A?
解决方案:一般而言,类别 B 若符合以下一个(也有可能是多个)条件,有权责要创建物件 A:
B的实例包括A的实例,或是合成聚合(compositely aggregates)A的实例B的实例会记录A的实例B的实例密切的使用A的实例B的实例有A的实例初始化时的信息,在创建物件时会传递给A的实例
例:ProductBacklog 的实例由 Project 的实例创建,因为 aggregation
相关模式或原则:低耦合性、工厂方法
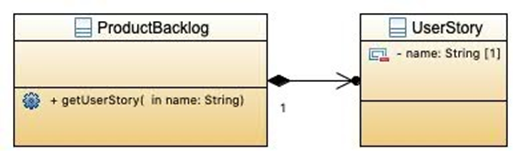
2. 信息专家 info expert
问题:分配职责给物件的基本原则是什么?
解决方案:将职责分配给具有履行职责所需信息的类。说白了就是谁需要这个信息,谁去执行职责呗。
- 信息专家(Information expert)是决定如何分配职责(给方法、字段等)的原则。
- 应用信息专家的原则,常见指定职责的作法是针对特定的职责,确认要实现此职责要有什么信息,以及信息存在的物件。
- 这会将职责分配到有最多和职责有关信息的物件、
相关模式或原则:低耦合性、高内聚性
例:ProductBacklog 类需要用户故事,所以这个类负责 getUserStory()
3. 低耦合性 low coupling
耦合性就是指,元素之间的连接、依赖等关系强不强。
问题:如何最小化变更带来的影响?
解决方案:分配职责的时候要注意,让不必要的耦合保持较低水平。
如果 getUserStory() 不是由 ProductBacklog 负责的而是由 USICMSystem 负责的,会怎么样?
由于系统要获取用户故事,首先要找到是哪个项目,然后再找到是哪一个 backlog,才能从 backlog 板上找到这个用户故事,过程比较繁琐,中间步骤多,于是导致耦合性高。
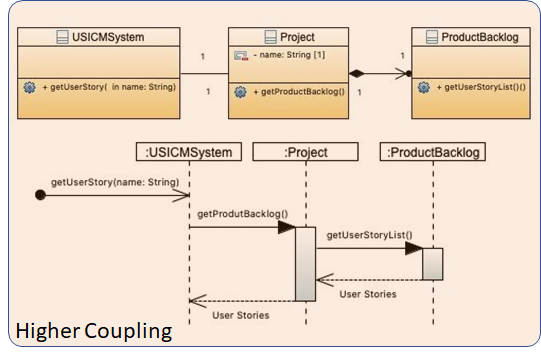
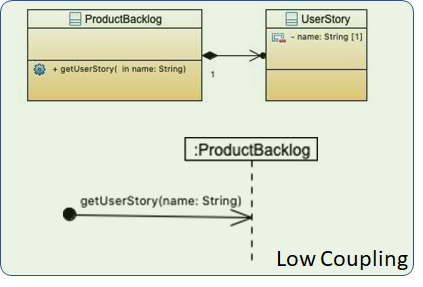
但是假如 ProductBacklog 来负责获取用户故事,就比较直接,耦合性低:
4. 控制器 controller
问题:UI 层以外,哪个对象要首先处理输入系统事件?
解决方案:把 root object(或者主要子系统,或者软件运行的设备)视作控制器。将责任分配给控制器。
例子:根对象作为响应输入的控制器。

相关模式或原则:命令模式、外观模式、层、纯虚构
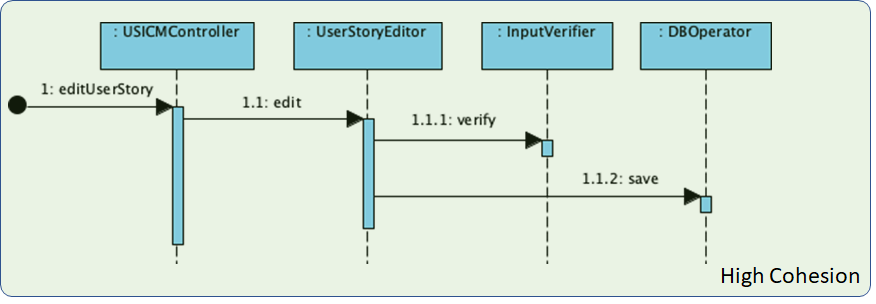
5. 高内聚性 high cohesion
内聚性就是指,不同元素的操作在功能上的相关性,以及一个元素要执行多少工作量。
问题:如何保持对象的专注、可理解性、可管理性,以支持低耦合性?
解决方案:将程序分解为类和子类,再分配任务,这是增加系统内聚性的一种方式。
比如,对于 editUserStory() 操作,如果 USICMController 一个类完成所有步骤,那么内聚性就比较低,不好:

但是假如用其他类和子类来分别负责不同的几个步骤,那么内聚性就比较高
6. 多态
问题:如何处理依类型的变化?如何产生可可插拔的软件组件?
解决方案:当一些行为会因为类型(类别)而变化,用多态运算符将此职责分派到类型出现变化的类型。(多态有许多的定义,在此处的定义是 “在不同物件上的服务给予相同的名字”)
例:比如用户故事可能是用文件的形式直接存的,也可能是存在数据库里面。这两种的操作对应的职责显然是不一样的。那就用两个新的类型去分别处理。
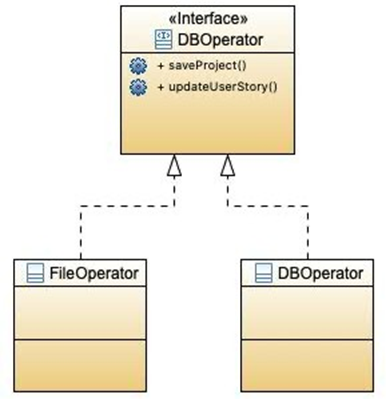
这样可以很容易的进行扩展,也可以在不影响客户端的情况下,添加新的实现。
7.8.9. 纯虚构、中介、保护变化
纯虚构(pure fabrication)就是指,当现在的解决方案,在高内聚性、低耦合性上做的不够好,该怎么办的问题。这可能是由于一些乱七八糟的职责导致的。解决办法是,创建一个不在领域模型当中的类,用这个类去完成这些杂七杂八的职责。
中介(indirection)的问题是,在二个或多个物件之间,要如何分配职责才能避免耦合?以及如何将物件解耦,才能支持低耦合度,且维持较高的复用潜力?答案是,职责分配给二个或多个组件之间的中介物件或服务,让组件之间不会直接耦合。
保护变化(protect variation)的问题是,如何设计物件、子系统和系统,让组件的变化或不稳定性不会对其他组件有不好的影响?解决方法是,预测什么会导致不稳定,围绕这个创建稳定的接口。
SOLID
SOLID 原则可以让软件更易理解,在进行扩展的时候更清晰可读,是敏捷开发以及自适应软件开发的基本原则的重要组成部分。
| 首字母 | 指代 | 概念 |
|---|---|---|
| S | 单一功能原则 | 对象应该仅具有一种单一功能 |
| O | 开闭原则 | 软件应该是对于扩展开放的,但是对于修改封闭的 |
| L | 里氏替换原则 | 程序中的对象应该是可以在不改变程序正确性的前提下被它的子类所替换的。 |
| I | 接口隔离原则 | 多个特定客户端接口要好于一个宽泛用途的接口。 |
| D | 依赖反转原则 | 一个方法应该遵从“依赖于抽象而不是一个实例”的概念。依赖注入是该原则的一种实现方式。 |
SOLID-S:单一功能原则
每个类、每个模块,应当只专注于一项任务。每个模块都只负责一部分。
可以实现高内聚性。
SOLID-O:开闭原则
软件对于扩展,应当是开放的;对于修改(影响客户端),是封闭的,这意味着一个实体允许在不改变它的源代码的前提下变更它的行为。
这个例子,不好,因为如果多一个图形,那么 AreaCalculator 就要进行对应的修改以适配新的图形

更好的办法是,用图形本身的类,实现计算面积的方法,然后 AreaCalculator 类直接调用它

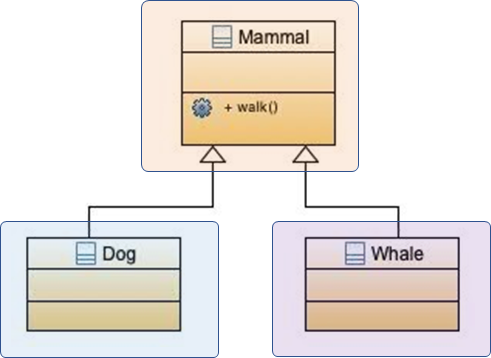
SOLID-L:里氏替换原则
程序中的对象应该是可以在不改变程序正确性的前提下被它的子类所替换的。
像这个设计就不合适,因为 whale 是鲸鱼,不会走路。所以不适合直接作为哺乳动物的子类型。
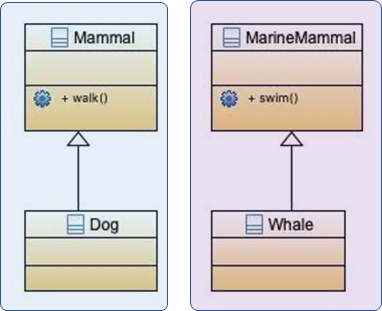
所以改成这个样子,多创建一个类(水中哺乳动物)才对。
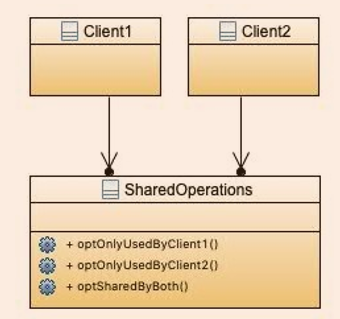
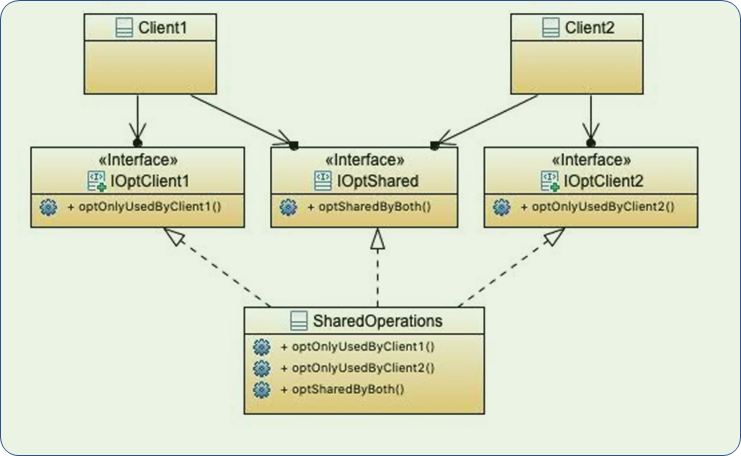
SOLID-I:接口隔离原则
多个特定客户端接口要好于一个宽泛用途的接口。不应强迫客户端依赖它们不使用的接口。
像这样,类当中有的方法只有一个用到,就不好:
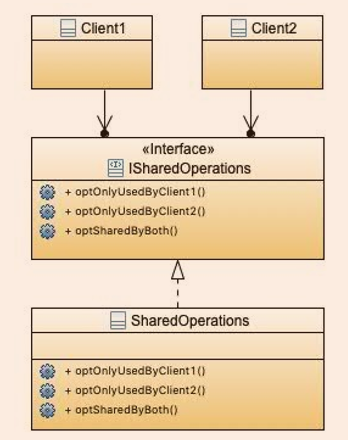
改一下,先把一个类拆成(类+接口的样子),然后接口再拆分成多个,看起来就好多了:
补充:组合 vs 继承.
企鹅是一种鸟,但是不会飞呀(除非你认为跳起来二十厘米扑腾手也算飞起来)

狗,虽然是陆地上的动物,但是水性很好!

所以像如下的这个类继承的设计,就不是很好。当涉及到的动物种类越来越多,总有一些奇怪的特例发生。

所以,保留这些具体的动物类,再创建一些能力类,就会好很多:

但是这样还有一个缺点,乱七八糟的类太多的,内聚性不足。
把聚合删掉,把各种能力拆成接口,然后用一个能力类来 implement:
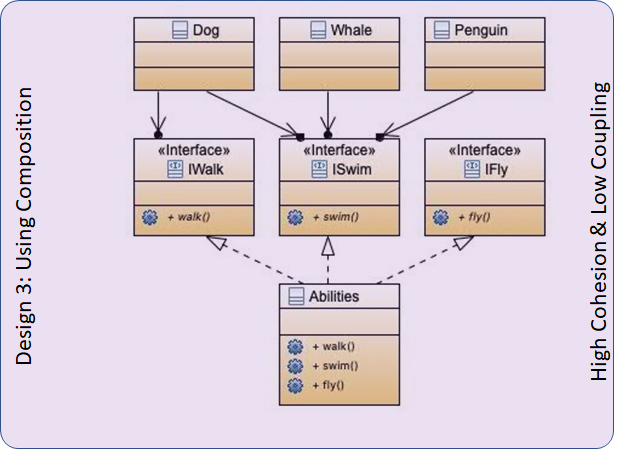
很好!
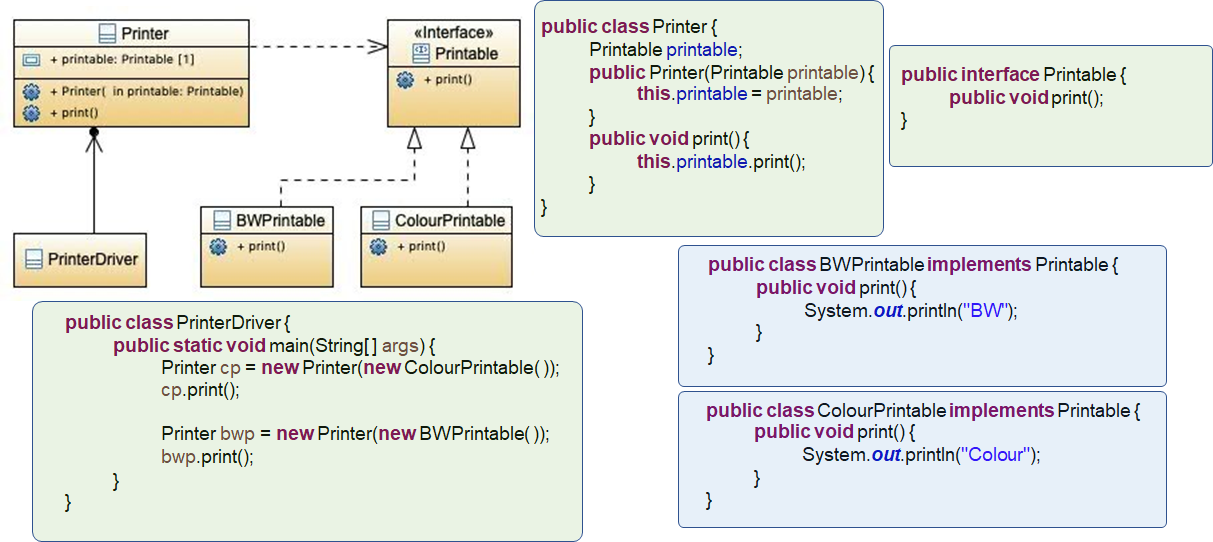
SOLID-D:依赖反转原则
依赖反转原则是指一种特定的解耦(传统的依赖关系创建在高层次上,而具体的策略设置则应用在低层次的模块上)形式,使得高层次的模块不依赖于低层次的模块的实现细节,依赖关系被颠倒(反转),从而使得低层次模块依赖于高层次模块的需求抽象。
代码应当依赖于抽象,而不是抽象依赖于代码。该原则颠倒了一部分人对于面向对象设计的认识方式。
简单地说,在面向对象的编程当中,上层会调用下层。所以,面向过程的编程当中,上层依赖下层。于是一旦下层发生了变化,那么上层也会有比较大的变化。
相反,在 OOP 当中,是下层依赖于上层,即代码依赖于抽象。这样如果下层做了更改,抽象(上层)可以不变,于是程序也不会有很大的变化。
也就是说,依赖反转原则,可以降低程序与细节之间的耦合。
例子没搞懂??
不好(类继承会产生强依赖、高度耦合的关系):

好
面向对象设计总结
- GRASP 比较注重责任分配,是一种责任驱动设计(RDD)的思想
- SOLID 与 GRASP 有许多重合的部分,比如都对于高内聚、低耦合有要求