Lecture 5. 汇编语言 Part4:整数,实数,字符串
整数
之前打印整数的程序,可以略加修改,使之可以打印负数:
.MODEL medium
.STACK
.DATA
ten word 10
neg1 word -1
.CODE
.STARTUP
mov ax, 32768
call Print
.EXIT
Print:
push bx
push cx
push dx
cmp ax, 0
jge notneg
push ax ; 如果是负数,就先打一个负号出来
mov ah, 02h
mov dl, '-'
int 021h
pop ax
mul neg1 ; 变号,也可以直接执行指令 neg
notneg:
cmp ax, 0
jz iszero ; 特判,如果要输出的是零
mov cx, 5
again:
mov dx, 0
div ten
push dx
loop again
mov cx, 5
again2:
pop dx
cmp dx, 0
je ignore ; 忽略前导零
or dx, 30h
mov ah, 02h
int 021h
ignore:
loop again2
jmp notzero
iszero:
mov ah, 02h
mov dl, '0'
int 021h
notzero:
pop dx
pop cx
pop bx
ret
END
字符串
字符串存储当中,第一个字节表示字符串的长度,最后跟着一个空字节(0)表示结束。在内存中,这些字节连续。
SI 与 DI 寄存器可以用于字符串的操作。S 与 D 分别代表 Source 和 Destination。
LEA 指令
加载有效地址,语法是 lea si/di, label
MOVSB 指令(cisc)
move string byte,用于把 DS:SI 位置上的内容复制到 ES:DI 上。
若方向标志 DF=0(默认状态下),则 SI 与 DI 会增加;反之若 DF=1 则 SI 与 DI 降低。
REP 修饰符,可以放在字符串指令之前,作用是将这条指令重复 CX 次。比如:
课件当中着重强调,movsb 是 CISC 的。ChatGPT 说:
movsb指令通常被归类为 CISC(复杂指令集计算机)指令。在 x86 汇编语言中,
movsb是字符串操作指令集的一部分。它用于将源索引 (SI) 所指向的内存位置的字节移动到目标索引 (DI) 所指向的内存位置。它还根据方向标志 (DF) 自动递增或递减索引寄存器 (SI和DI)。CISC 指令以其能够在单个指令中执行复杂操作而闻名。虽然
movsb指令本身的操作很简单,但它是 x86 架构丰富指令集的一部分,该指令集包括各种寻址模式和功能。这导致movsb指令及 x86 指令集被归类为 CISC。
例子:课件上的
复制字符串 string1 到 string2 当中
.MODEL medium
.STACK
.DATA
string1 db 'This is a test$'
string2 db 'abcdefghijklmnopqrstuvwxyz$'
.CODE
.STARTUP
mov dx, OFFSET string2
mov ah, 09h
int 021h ; BIOS print,遇到 $ 停下
mov ax,ds ; 令 ES = DS
mov es,ax
LEA SI, string1 ; Offset
LEA DI, string2
CLD
mov CX, 15
REP MOVSB
mov dx, OFFSET string2
mov ah, 09h
int 021h ; BIOS print,遇到 $ 停下
.EXIT
END
CMPSB 指令
比较 DS:SI 与 ES:DI 位置上的字符串(单个字符)是否相等,结果反映给 flag。
通常配合 REPE(repeat while equal)与 RENE(repeat while not equal)来使用。这俩修饰符也跟 cx 有关。换句话说,是在 cx != 0 的基础上,执行循环。
例子:GPT 给的
比较字符串 string1 和 string2 是否相等
.MODEL small
.STACK
.DATA
string1 DB 'Hello'
string2 DB 'Hella'
message1 DB 'Strings are equal$'
message2 DB 'Strings are not equal$'
.CODE
.STARTUP
MOV AX, @DATA
MOV ES, AX ; 令 ES=DS
LEA SI, string1
LEA DI, string2
MOV CX, 5 ; 比较前五个字符
REPE CMPSB ; Compare byte at [DS:SI] with byte at [ES:DI]
JE equal ; If strings are equal, jump to 'equal'
; Strings are not equal
MOV DX, OFFSET message2
MOV AH, 09h
INT 21h
JMP exit ; Jump to 'exit'
equal:
; Strings are equal
MOV DX, OFFSET message1
MOV AH, 09h
INT 21h
exit:
MOV AH, 4Ch
INT 21h
END
乘法除法运算
CISC 的处理器可能提供了乘法和除法指令(比如 mul),但是 RISC 不一定。
实现乘法

八位二进制数乘以八位二进制数,就是八次循环,每次循环检查乘数最低为是否是 1:
- 是 1,那就把被乘数累加一次,然后被乘数翻一番
- 不是 1,不累加,直接把被乘数翻一番
RISC 代码
时间复杂度是 $O(\lg w)$ 的,$w$ 指位长
.STARTUP
mov ax, 0
mov dx, 100 ; Multiply dl by bl result in ax.
mov bx, 123
mov cx, 8
back:
rcr dx, 1 ; move lsb dx into c
jnc over
add ax, bx
over:
shl bx, 1 ; multiply bx by 2
loop back ; repeat 8 times
; now ax = dx * bx
call Print
.EXIT
END
对应 CISC 代码
.STARTUP
mov dl, 100 ; Multiply dl by bl result in ax.
mov al, 123
mul dl ; now ax = dl * al
call Print
.EXIT
END
注意:回顾 8 位乘法,结果是 16 位,保存进 ax
| 规模 | 被乘数 | 乘数 | 积 |
|---|---|---|---|
| byte | AL | r/m8 | AX |
| word | AX | r/m16 | DX:AX |
| dword | EAX | r/m32 | EDX:EAX |
除法
代码实现比较难,课件上只讲了原理
- 被除数 1101
- 第一位减去 101,不够,写 0
- 前两位减去 101,不够,写 0
- 前三位减去 101,够了,写 1,做减法,被除数变成 0011
- 第四位减去 101,不够,写 0
- 没位了,商就是 0010,余数就是现在的被除数 0011
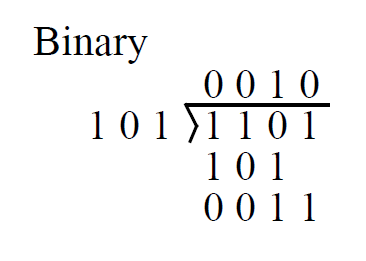
浮点数的表示

IEEE 把所有规范化的实数都表示为 $1.xx \times 2^{yy}$ 的形式。IEEE 把实数表示分成三个部分,分别是符号、指数 Exponent、大小 Significand。指数偏移值是指数位的长度 $l$ 的函数:$(2^{l-1}-1)$。
有三种类型
- 32 位的短实数,三部分长度分别是 $1,8,23$,规约范围 $-1.2\times 10^{-38} \sim 3.4\times 10^{38}$
- 64 位的长实数,三部分长度分别是 $1,11,52$,规约范围 $-2.3\times 10^{-308}\sim1.7\times 10^{308}$
- 80 位超长实数,三部分长度分别是 $1,27,23$,规约范围 $-3.4\times 10^{4932}\sim1.1\times 10^{4932}$
由于指数部分采用了偏移(用 $0\sim255$ 代替 $-127 \sim 128$),这样指数的大小就可以直接按照字典序(或者像整数一样)进行比较。指数的大小一旦确定,浮点数的大小关系也就确定了。从而加快浮点数大小的比较速度。
例:用 IEEE 标准的 32 位浮点数表示 178.625
- 正数。符号位 $\color{black}\colorbox{#c6fcff}{0}$
- 把 178 转化为二进制:$10110010$
- 把 0.625 转化为二进制:$0.101$
- 于是 178.625 的二进制就是:$10110010.101$
- 移动小数点,把这个二进制换成科学计数法表示:$1.0110010101\times 2^7$,取前半部分的小数部分 $\color{black}\colorbox{#ffb0ae}{0110010101}$ 作为 Significand 部分的值。由于不够长,补 13 个零。
- 计算指数偏移值:$7+127=134$,转化为二进制是 $\color{black}\colorbox{#a2ffa0}{10000110}$
- 拼起来三个部分:$\color{black}\colorbox{#c6fcff}{0}\colorbox{#a2ffa0}{1000 0110}\colorbox{#ffb0ae}{01100\ 10101\ 00000\ 00000\ 000}$
8087 协处理器
计算机当中,除了微处理器(microprocessor),还可以有协处理器(coprocessor)。协处理器通过提供特定硬件支持(当然也有额外的指令集),与微处理器共同运作,起到辅助运算的作用。
比如 FPU 和 GPU 都是协处理器。FPU 用来处理浮点数(比如 8087 协处理器),GPU 用来处理图形。
从 486 开始,所有的 Intel 处理器都集成了协处理器。为了区分一条指令是微处理器的还是协处理器的,协处理器指令的 opcode 都是 11011 前缀。
结构
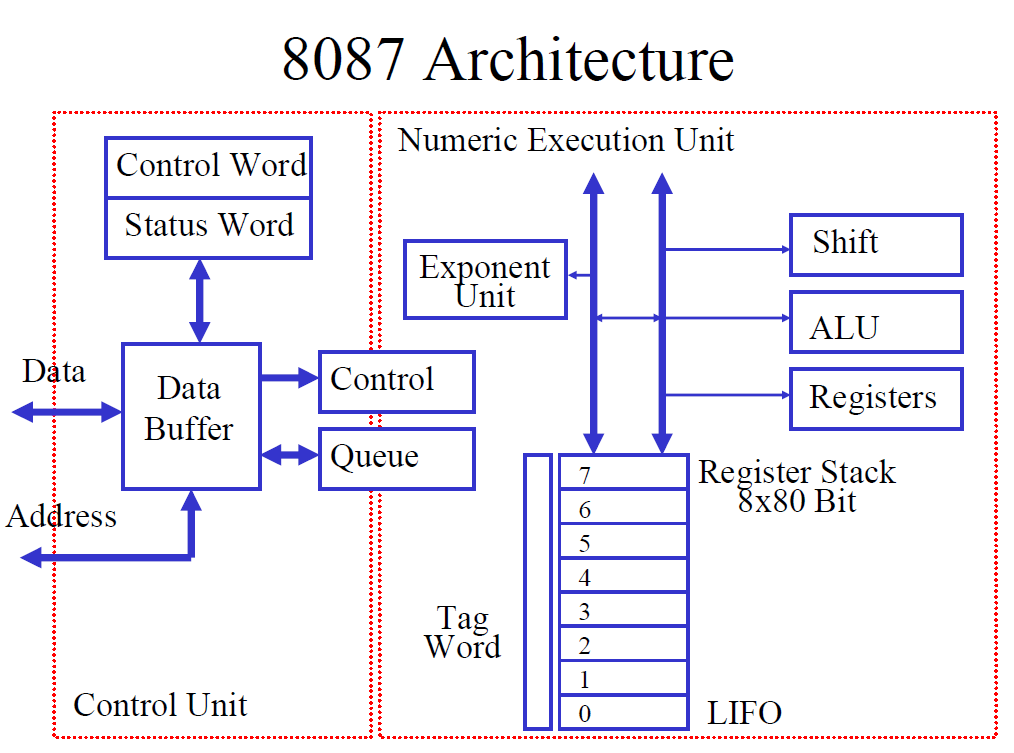
状态字组 status word
一个寄存器,两个字节,16 位。
就像是 8086 里面的 flag 寄存器,包含异常标志等。

控制字组 control word
一个寄存器,两个字节,16 位。
用于控制精度、舍入规则等。

栈
8087 还自带了一个栈,栈当中每个元素都是 10 字节,栈始终有 8 个位置。
每次压入新数据到栈当中,都不会改变栈的大小(依然是 8),但是新数据会覆盖旧数据。就像是移位运算那样。
在 MASM 汇编代码当中,ST(0) 始终表示栈顶,ST(1~7) 表示栈中其他元素。
8087 实用指令
FADD S1/D, S2表示把两个 S 进行加法运算,结果存入 D(S1=D),相当于S1 += S2。如果没有指定 两个 S,那么就相当于ST(0) += ST(1)FSUB S1/D, S2相当于执行S1 -= S2FSUBR S1/D, S2与上面相反,相当于S1 = S2 - S1- 此外还有
FMUL,FDIV,FMULP,FIMUL,FDIVR,FDIP,FIDIV等