Lecture 19.20 内存管理二:虚拟内存等(46 页)
三个概念:文本、栈、堆
- 文本,就是程序的代码。一般是静态的。
- 栈,通常大小是固定的,进程使用栈来创建 frames 来保存参数和局部变量,并在调用函数的时候返回链接地址。由于栈是 LIFO 的,所以 allocation 和 deallocation 都挺快的。
- 栈是每个线程独享的,而堆是线程之间共享的。堆的大小也是可变的,用于创建动态的数据结构和对象。堆上的变量相当于全局变量,即使函数结束了,也会依然存在。堆的管理更复杂一些。
Allocation
memory manager 要如何监测哪一块内存是 free 的,哪一块不是呢,并且如何给进程分配?主要有三种方法:
- bit maps
- linked list
- buddy system
位图 BitMaps
就是把内存分成若干个大小一致的小块(叫做 allocation unit,比如 1024 字节)。然后用一个名叫 bitmap 的 bitset 数据,来表示每个小块是 free 的还是 not-free 的。1 表示 used,0 表示 free。内存的总大小以及小块的大小决定了 bitmap 的长度。
allocation unit 设大了会导致浪费,设小了会导致 bitmap 太长从而降低效率。
0 代表 free,1 代表 not free,于是在 bitmap 里面找 free 的空间相当于找连续的 0. 有的处理器有专门干这个的指令。allocation 和 deallocation 分别对应设一和置零。
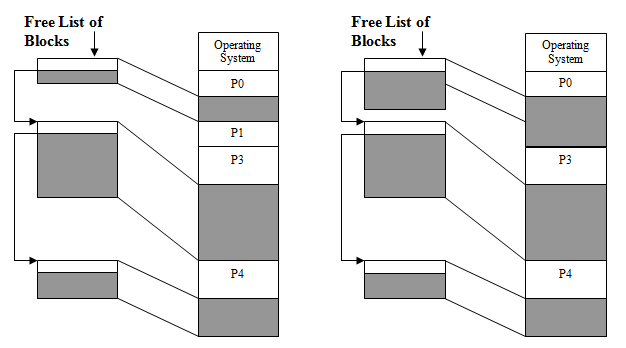
链表
维护一个链表,链表当中的每一个元素都表示一个 free 的分区的大小和位置。
链表存储在哪里呢?由于链表每个元素之间都是用指针联系起来的,所以存储链表只需要存储链表头元素的指针。这个指针也就几个字节,随便找一个 free 分区存进去就好了。
allocation 也就是要查找 free 的分区,就要遍历这个链表,从中找到一个足够大的。
而 deallocation,不是简单对应着往链表里面插入元素。deallocation 可能要寻中链表中的跟要回收的内存挨着的区域,然后合并起来,如图
几个术语
- 最优适应 best fit,就是把进程放到满足大小要求的最小的那个 block 里面。
- 最差适应 worst fit,就是把进程放到最大的 block 里面
- 首次适应 first fit,在扫描过程中,选择第一个足够大的 block
- 邻近适应 next fit,是 first fit 的一种特殊情况,每次扫描从上次结束的地方开始
遍历链表的时候,选择哪一个算法比较好?
不同的选取方法可能导致将来不同的紧缩(compaction)次数。要让将来紧缩次数尽量小。
比较:位图 vs 链表
| 位图 | 链表 | |
|---|---|---|
| 大小 | 大小固定,与内存占用无关 | 大小随内存占用的变化而变化 |
| 效率 | allocation 只需要遍历位图;而 deallocation 特别快 | 如果小片段太多,那么 allocation 的时候会导致遍历链表很慢;而且 deallocation 的时候需要完整的分析链表进行合并 |
| 内部碎片 | 平均每个进程半页内部碎片(少的 0,多的 p-1) | 没有内部碎片 |
同伴系统 Buddy system
buddy system 是一种妥协(compromise)的方案。它可以动态调整分区的大小,从而比位图灵活;但是对于大小也有一些限制,从而 allocation 和 deallocation 没有链表那么麻烦。
在 buddy system 当中,使用了若干个链表,第 $i$ 个链表仅维护大小是 $2^i$ 的内存块。所以如果有一个进程需要 1M 的内存,那就至少需要 21 个链表(0~20)。
分页架构 paged architecture
用 base 与 limit 来进行内存分配存在一定的缺陷,因为进程分配的地址只能是一个连续的段。
如果硬件支持,可以使用分页架构。分页架构的关键是一种映射机制(mapping mechanism)。
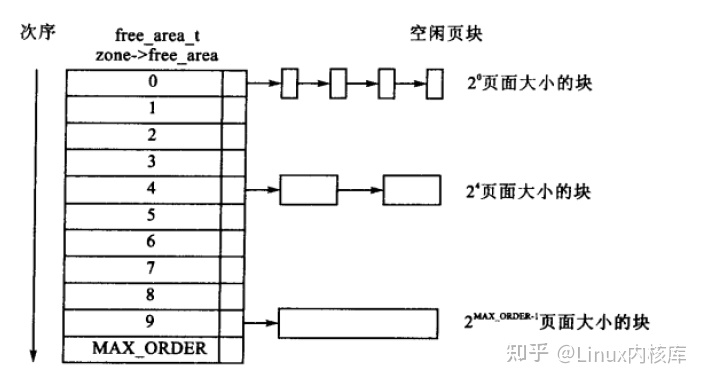
详细来说,进程使用的逻辑内存,被分为许多大小固定的比较小的单元(512B 或 8KB),这每个单元叫做页面(page)。于是一个进程的地址空间就由许多页面组成。
物理内存也可以说页,但是为了避免混淆,最好说是页帧(frame)。进程地址空间内的 page 可以通过 CPU 当中的内存管理单元(MMU)映射到物理内存对应的页帧。

页表 page table
页表是一种用于存储映射信息的数据结构。每一个进程都拥有一个页表。
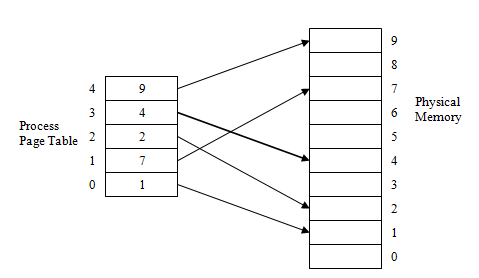
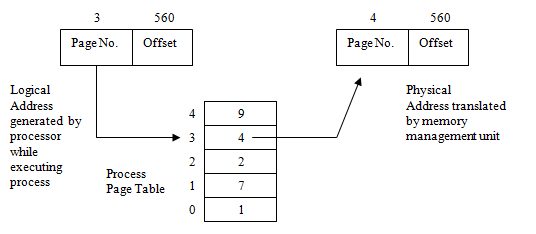
内存地址分为两个部分,一个是页面编号(page number),另一个是偏移(offset)。MMU 负责将从页表当中查询逻辑页面编号对应着哪一个物理页编号。偏移量不变。于是就得到了真实的物理地址。
分页架构的优点
- 安全。由于每个进程都有一个页表,所以每个进程只能被映射到自己的地址空间,不同进程之间不能相互访问其地址空间。
- 分配给进程的内存空间可以由若干个页组成,这些页可以不是连续的,可以随即散布在整个物理内存里。因此 easy to keep track of free space 以及 easy to allocate space。
- easy to re-allocate or expand 内存空间
分页架构的缺点
- 页表可能本身比较大,需要保存在主内存当中,这是额外的开销
- 需要先访问一次页表再根据页表去访问指定内存位置,因此总共是两次访问,造成了性能消耗;而且映射本身也会有一定的性能消耗。
- 进程不一定能使用完所有的页的内存。平均产生半页内部碎片。
虚拟内存
假如所有进程的逻辑空间都扔到内存里,那么内存可能很快就不够用了。
在实际使用中,一个进程所访问的内存,在短时间内,通常仅仅是一小部分。这叫做 引用局部性(locality of reference)(CS253 也提到过)。因此可以只把这一小部分放到内存里,暂时不用的放到别的地方,比如硬盘里,需要用的时候,再加载到内存。硬盘里面的那部分暂时不用的内存,叫做 swap file。
于是,根据这样的思想:
- 进程所使用的逻辑地址,可以超过物理内存总量
- 可以同时运行更多程序了
- 要按照引用局部性的原则保留内存空间
修改页表结构
页表当中的每一个元素,要增加一个 bit 的信息,用于表示这个页面编号对应的物理内存地址(valid or invalid),是在主存里,还是硬盘里。

如果是 valid 的,那就直接访问对应的物理内存;如果是 invalid 的,那就会产生一个 page fault 的中断。这个中断的处理程序会尝试把硬盘上虚拟内存的这一部分替换到物理内存里面去,但如果访问不合法,就可能直接终止进程。
工作集 working set
工作集是指一个时间段内,进程被分配的内存。
工作集的大小不能超过此时可用物理内存的总量,最小值由处理器结构决定。
页面置换机制 page replacement
有时候一个进程需要使用的内存比较多,但是可能剩余可用物理内存不够了,或者操作系统为了公平给这个进程的可使用的最大内存做了限制。这时进程如果还想继续运行,就需要把暂时不用的扔到虚拟内存(硬盘)里面去,然后用腾出来的新的位置。
选哪一个页进行替换呢?这就是 page replacement algorithm 要研究的东西了。
- 首先,肯定不能把常用的页替换出去。要不然就换频繁的除法 page fault 中断,触发这个中断就需要访问硬盘。众所周知,硬盘非常慢。
- 此外,尽量让将来 page fault 的次数低一些。
- thrashing 也是 CS253 当中提到过的一个概念,意思是说在内存和硬盘之间频繁的移动。这也会严重降低性能,应当避免。working set 太小就容易导致 thrashing,调大就好了。
关于效率的一个小计算
注意理解「dirt」的含义,即失败率,需要算个期望。

最优页面置换 optimal page replacement
就是让 page fault 最少的一种算法。
但是实现这个算法很难,是超纲的。
那这个东西有啥用?答案是可以计算出理论最优值,然后用其他算法的结果进行比较,以评价其他算法的好坏。
比如下图对于这个 reference string,最优页面置换算法的 page fault rate 仅有 50%,那么其他算法如果可以接近 50%,那就可以接受。

FIFO 算法
说白了就是把当前最老的一页给替换出去。
实现的话,只需要给每个页记录一下进来的时候的时间戳。或者用 circular array 储存这个 working set 也可以。所以实现起来还是挺简单的。
但是:FIFO 算法可能对于大多数程序都不是很适用,性能上不咋地。
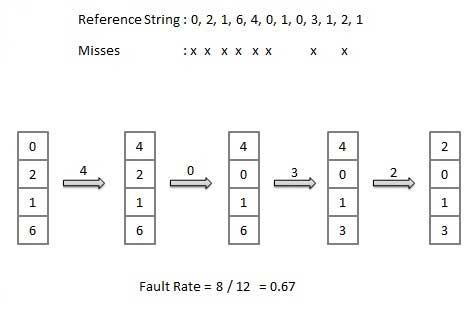
比如还是刚才那个 ref string,用 FIFO 算法,page fault rate 高达 75%

LRU 算法
LRU 就是 Least Recently Used 的缩写,表示最近使用。它的思想就是,如果一个页刚刚被使用过了,那么它过一会还要被使用的概率是很大的(比如对于代码有循环的情况)。所以就不把他换走。
所以,最近被使用的留下来,最长时间未被使用的踢出去(认为很长时间没用过的,之后被用到的概率也不会很大)。
在实现上,也需要用一个时间戳,但是每次访问该位置内存之后,都要对时间戳进行更新。
上面的 ref string 如果使用 LRU 算法,page fault rate 是 66.7% 左右,还可以。
LFU 算法
LFU 算法的 F 是 frequently 的意思,表示一段时间内。
LFU 算法会把一段时间内使用次数最少的踢出去。它认为一段时间内几乎没用到过的东西,接下来应该也不会被用到。
但是这也有一个很显然的缺点。假如选取的时间段包含了 1000 条使用记录,然后接下来会持续一会用到之前从来没有出现过的。那么这个进来之后可能又立马被开出去。
这种算法在实现方面需要的不是时间戳了,而是一个 counter。
Belady 异常:Belady’s Anomaly
直观的想象一下。如果一个进程被分配到的页表多了,那么这个进程产生 page fault 的概率应该就会低了。然而在应用 FIFO 算法的时候,反而可能页表越多,page fault 越多。可以参考如下对比图

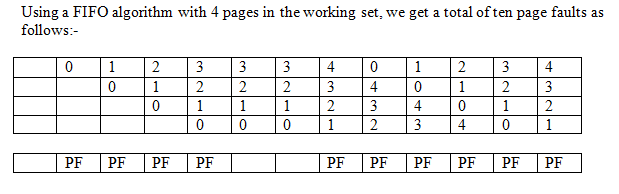
第一张图的页表有仨,9 次 PF;第二张图四个页表,10 次 PF。