Lecture 12. 解决临界区问题的算法(25 页)
解决临界区问题的办法应当满足哪些条件
- a) 互斥 Mutual Exclusion,就是 critical section 同一时间只能被一个线程运行
- b) 进步 Progress,就是说假如现在没有线程在 critical section 里面运行,而外边有想要进入 critical section 的,那么只有不在 remainder section 里的可以参与选择。
- c) 有限等待 Bounded Waiting,就是如果一个线程说想要运行 critical section,必须保证在里面不无限占用
我们先考虑如何解决双线程,再解决多线程。
双线程
用 $i$ 和 $j$ 分别表示两个线程的 id。
对于第二版火车方案
int turn;
while (turn != i) wait();
// critical section
turn = j; // 不管谁想接下来执行,都让另一个执行,可能导致 lockstep
// remainder section
对于第三版火车方案
bool flag = {false, false};
flag[i] = true;
while (flag[j]) wait(); // 假如 flag[i] = flag[j] = true,就有死锁
// critical section
flag[i] = false;
// remainder section
结合两个方案
这个方案保证了:
- Mutual Exclusion
- Progress
- Bounded waiting
bool flag = {false, false};
flag[i] = true; // 线程自主决定是否想要执行,避免了 lockstep
turn = j;
while (flag[j] && turn == j) {
// 这个循环不会执行,因为 flag[j] = true 的话,turn 会被另一个进程设置成 i
// 所以就避免了死锁
// 同时,后来的会把 turn 设成另一个,所以先来的那个肯定先执行,从而等待时间也是 bounded 的
wait();
}
// critical section
flag[i] = false;
// remainder section
n 线程(bakery algorithm 面包店算法)
就相当于有好多人去吃淄博烧烤。由于淄博烧烤太过火爆,游客必须排号。号码从 1 开始递增,互不相同,每个游客手中的号码牌决定了就餐顺序。假如一群人同时到达烧烤店,那就根据这些人的 id 来确定顺序。
bool choosing[n] = {false};
int number[n] = {0};
void lock(int i) {
choosing[i] = true;
number[i] = max(number) + 1;
chossing[i] = false;
for (int j = 0; j < n; ++j) {
while (choosing[j]) wait();
while (number[j] && pii(number[j], j) < pii(number[i], i)) wait();
}
}
void unlock() {
number[i] = 0;
}
lock();
// critical section
unlock();
// remainder section
使用
Entering数组是必须的。假设不使用Entering数组,那么就可能会出现这种情况:设进程 $i$ 的优先级高于进程 $j$ (即i<j),两个进程获得了相同的排队登记号 (Number数组的元素值相等)。进程 $i$ 在写Number[i]之前,被优先级低的进程 $j$ 抢先获得了 CPU 时间片,这时进程 $j$ 读取到的Number[i]为 $0$,因此进程 $j$ 进入了临界区。随后进程 $i$ 又获得 CPU 时间片,它读取到的Number[i]与Number[j]相等,且i<j,因此进程 $i$ 也进入了临界区。这样,两个进程同时在临界区内访问,可能会导致 数据腐烂(data corruption)。算法使用了Entering数组变量,使得修改Number数组的元素值变得 “原子化”,解决了上述问题。
在多处理器系统上解决缓存问题
CS253 提到过:为了提升性能,计算机会把 DRAM 的内存里面的东西,复制到 SRAM 的缓存当中。
之前提到过的解决互斥的方法,都是软件层面的方法。这类方法有一个要求,就是必须每个线程访问到的用于控制的共享数据,都是相同的。
假如在多处理器系统上运行,每个处理器都有一块缓存,就会有多个缓存。这些缓存之间的值,相等吗?不能保证。
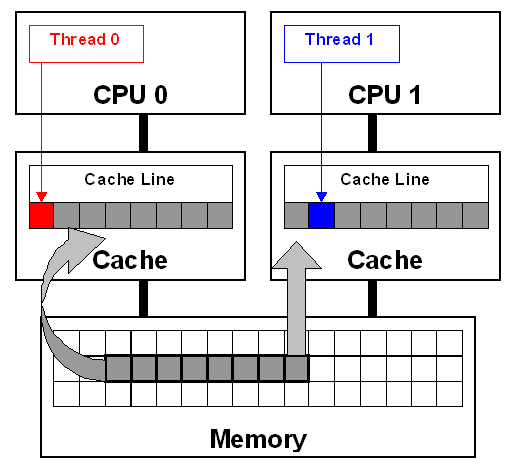
那咋搞?
屏蔽中断 disable interrupt
假如啊,还是在单核处理器上,那么直接禁用掉抢占(preemption)或者说禁用掉中断就可以了。于是正在运行的线程不会被打断,它可以轻松的设置这些控制类变量。
但是在多核处理器上,禁用中断不切实际,低效,且比较有风险。
原子指令 Atomic test-and-set
有个原子指令(就是执行过程不会被分割,一气呵成),可以用于对指定内存区域进行 test 和 set。test 说白了就是读取,set 就是设置值。test-and-set,这是硬件级别的指令。
它会把指定位置的值设置成想要的,并返回设置之前的值。
这个指令执行期间,相对于的内存区域是被锁住的,不会被别的进程访问到。
在代码当中,用 volatile 关键字声明的变量,不会被缓存。于是,弄一个公共的锁:
每个线程在进入 critical section 之前都尝试上锁(设为 true)。如果发现自己上锁之前已经被锁上了,那就等待。这个上锁的过程用 test-and-set 指令实现,即:
while (test_and_set(&lock, true)) wait();
// critical section
test_and_set(&lock, false);
// remainder section
注意,这种方法(自旋锁,spinlock),不能保证 progress 和 bounded-waiting。而且其实在多核处理器上的效率不是特别高。
xchg 或 swap
也是一种硬件级的指令,作用是在不可分割的执行过程中,交换两块内存区域的值。
bool lock = false; // 共享
bool key = true; // 每个线程独有
do { swap(&lock, &key); } while (key);
// critical section
swap(&lock, &key);
// remainder section
注意,这种方法(自旋锁,spinlock),不能保证 progress 和 bounded-waiting。
忙碌等待 busy waiting
以上介绍的所有方法都会导致忙碌等待,意思就是说 while 循环不断的检查是否满足条件。这对于性能是有一定影响的。
如果等了很久很久还没有等到,那可能就是一个死循环,操作系统可能要把这个线程掐掉。