Lecture 7. UNIX 的进程管理与进程间通信(30 页)
- 使用 C 创建、终止、控制进程
- Linux 操作系统的开机:创建第一个进程
- 不同的通信实现方法
进程间通信的常用模型有两个:消息传递模型和共享内存模型。
UNIX 的进程创建
流程
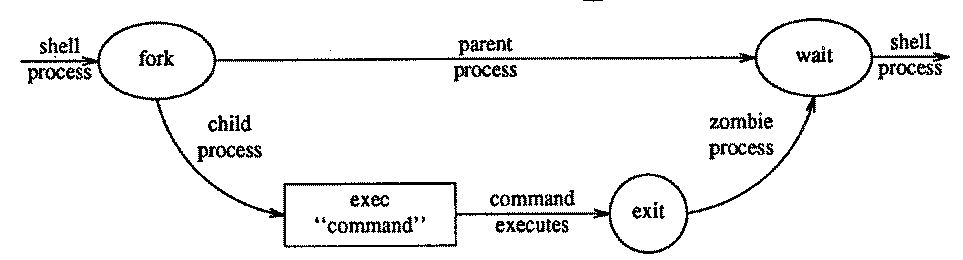
fork() 系统调用
- 每一个进程都有一个独一无二的 ID
- 在 C 代码当中,使用
fork()来创建进程,原有的的进程是父进程,新建的进程是子进程 - 子进程其实是父进程的一个副本(copy),父进程的所有东西都会被子进程复制,甚至 IO 描述符表也会被子进程复制一份。所以,在 IO 方面,父子进程具有相同的权限
- 顺带提一句,子进程是从
fork()之后的代码开始执行的 - 父子进程的区别在于
fork()的返回值。父进程返回的值是子进程 pid,子进程返回零。

exec() 系统调用
- 通常,对于 child 进程,
fork()之后,会再调用一下exec()。 exec()的作用是将指定的二进制文件加载到进程的内存当中(即替换掉现有的程序映像,会破坏原本内存的内容),然后执行它。- 采用
exec()的方式,两个进程可以以各自的方式运行,还可以相互通信。 - 由于原本内存的内容被覆盖了,所以执行
exec()之后一般不会返回控制,除非出现错误
wait() 系统调用
wait()会暂停掉当前的进程(把自己从就绪队列移除),直到它的子进程终止(suspend)。(在执行子进程且父进程不知道该干啥的时候使用)wait()执行完毕后,系统会回收掉僵尸(zombie)子进程的资源- 如果
wait()执行成功则返回 0,否则返回 1
C 语言实现
#include <stdio.h>
#include <stdlib.h>
#include <unistd.h> /* provides access to the POSIX API */
int main(int argc, char** argv) {
int pid;
pid = fork(); // 创建子进程
// 如果 fork 执行成功
// 就会有两个进程存在,除了 pid 都相同
// 父进程的 pid 非零
// 子进程的 pid 是零
if (pid < 0) {
printf("Fork failed");
exit(-1);
} else if (pid == 0) {
// 这是子进程
execlp("/bin/ls", "ls", NULL);
} else {
// 这是父进程
wait(NULL); // 等待子进程执行结束
printf("Child complete");
exit(0);
}
}
思考
如下代码,将会创建多少个子进程?
答案是, for 执行多少次,就输出几个子进程的 pid(互不相同)。因为子进程的 fork() 返回值是零,不会进入 if 分支。
#include <stdio.h>
#include <stdlib.h>
#include <unistd.h> /* provides access to the POSIX API */
int main(int argc, char** argv) {
int pid;
for (int i = 1; i <= 3; ++i) {
pid = fork();
if (pid != 0) {
printf("Process %d\n", pid);
execlp("/bin/ls", "ls", NULL);
}
}
}
Linux 系统开机
主引导记录(master boot record)
主引导记录(Master Boot Record,缩写:MBR),又叫做主引导扇区,是计算机开机后访问硬盘时所必须要读取的首个扇区,它在硬盘上的三维地址为(柱面,磁头,扇区)=(0,0,1)。
当完成开机自检(power on self test)和硬件识别(hardware identification)之后,第一个启动设备就会被选中。MBR 就位于这个设备的第一个扇区,这个扇区内的东西就会被读取。MBR 包含了 初始启动代码(initial bootstrapping code) 和 活动分区(active partition) 的信息。
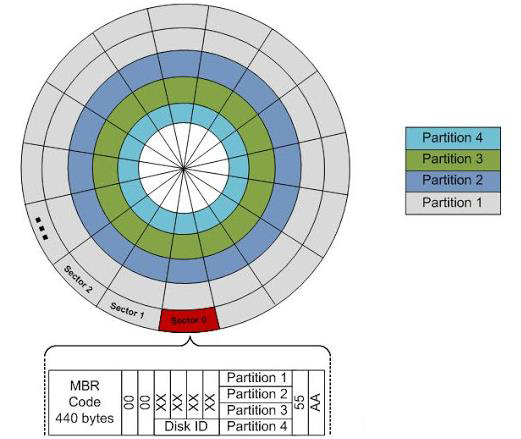
硬盘分区
比较重点的就是 MBR、empty、sda 三块内容

MBR
之前说过,一个扇区通常是 512 字节,现代设备可能是 4096 字节。所以第零个扇区,也就是 MBR 里面的代码肯定是要小于 512 字节的(440 字节 in fact)。开机的时候,基本输入输出系统(BIOS)就会读取这个扇区里面的初始启动代码并执行。
empty
之后还有 2047 或 255 个扇区(总共约 1KB),可能会用来存储额外的引导代码或者驱动程序。这里的内容不会被文件系统的格式影响。
sda1
约有 250MB 的空间,足够用来 locate 和 load 主引导加载程序(boot loader program)。用户会看到一个界面,提示用户选择一个操作系统。
Sequence 示意图如下
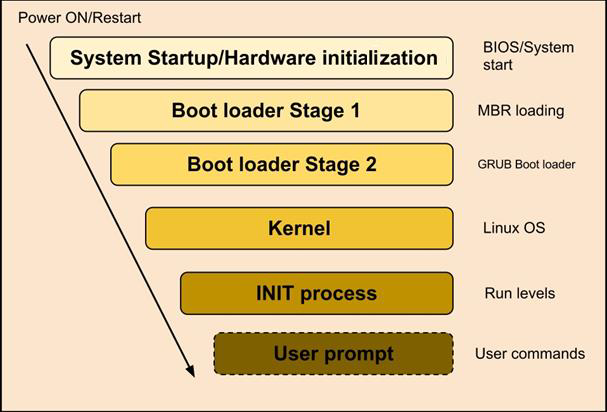
运行级别 Run Level
运行级别通常分为 7 等,分别是从 0 到 6,但如果必要的话也可以更多。
- 0,停机或关机状态
- 1,单用户,不联网,不运行守护进程,不允许非超级用户登录
- 2,多用户,不联网,不运行守护进程
- 3,多用户,正常启动系统
- 4,用户自定义
- 5,多用户,相较于三级,带图形界面
- 6,重启

Linux 系统开机的流程
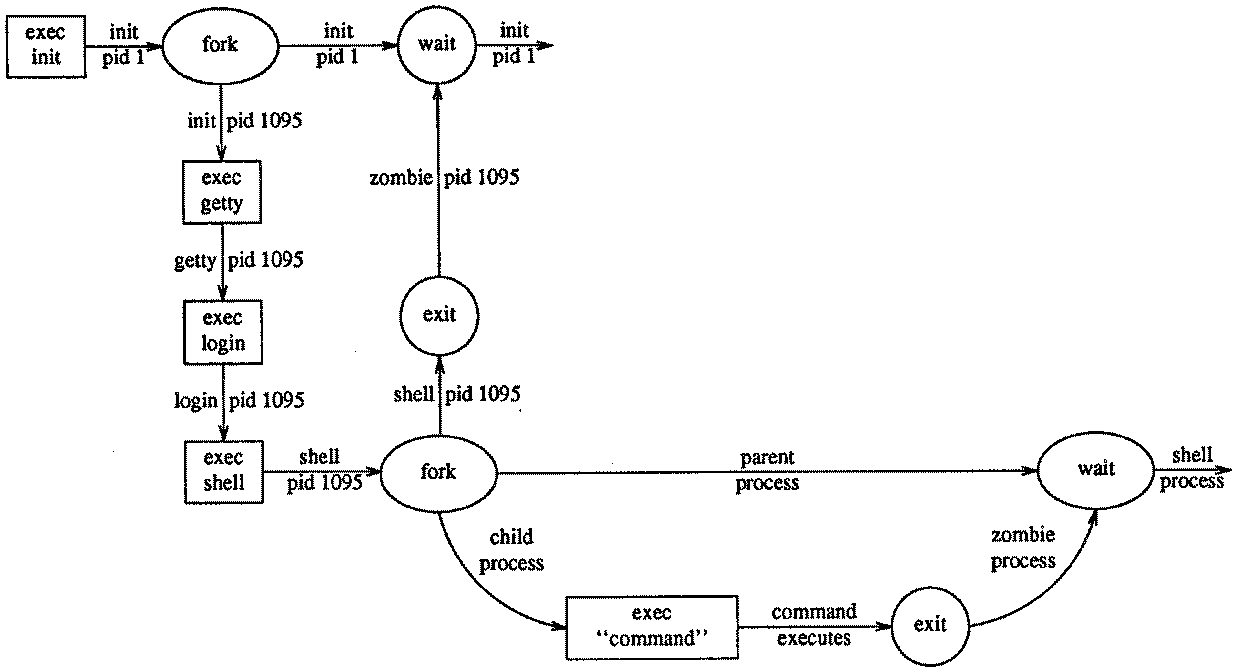
进程间通信
通信,即信息的交换或共享
并行计算、模块化应用、客户端访问服务器,等等方面,都涉及到进程间通信。
进程间通信主要有两种方式:
- 一个是利用共享的内存区域
- 另一个是使用操作系统提供的通信功能(explicit message passing primitives)
共享内存系统
操作系统建立一块特殊的内存区域,多个进程都具有访问权限。这个 区域一般是位于某一个进程的地址空间 内,其他进程把这个地址空间附加到自己的地址空间。

- 模型是面向应用的,适合于愿意分享内存的合作进程(所以通常是一个大型应用的若干组件,比如 chrome)
- 通过对内存的读写操作,进行隐式通信(Implicit)
- 高效率,无需通信协议
- 需要同步机制(做好协调,避免对同一地址的同时写入)
后面章节涉及到的 生产者-消费者问题,也与共享内存有关。
消息传递系统
对于不愿意共享内存的进程,或者不在同一台设备上运行的进程,就需要别的通信方式了。
消息传递设施(message passing facility),就像是中介一样,可以从一个进程的地址空间拿出东西来,然后放到另一个进程的地址空间里面去。比如,网络,就是一种中介。
消息传递系统的两个最基础的功能,是 send 与 receive。进程通过调用这个功能来实现消息的传递。更高级的一些东西,比如 远程过程调用(RPC,Remote Procedure Call) 也是通过这个实现的。
命名 Naming
消息传递可以是直接的,也可以是间接的。
- 直接的,就是指,进程 A 直接传给进程 B
- 间接的,就是指,进程 A 先把消息放到信箱(mailbox)C 里,另一个进程再去拿(但这个信箱不完全等于是共享内存区域,因为它可以是操作系统提供的,不属于某个特定进程)
- 可能是多个进程都放到信箱里,一个进程读,多对一;也可能是一对多
无论是直接传递还是间接传递,你都得说明,传给谁。也就是说,你得给每一个东西都起个名字(或者编号),然后调用 send() 或者 receive() 的时候,指明这个名字或者编号。
同步 Synchronisation
进程间通信可以通过调用 send() 和 receive() 这两个 原语(primitives) 来进行。这两个原语的实现可以实阻塞的也可以是非阻塞的。阻塞对应着同步,非阻塞对应着异步,这一点跟 CS335 里面还挺像:
- 阻塞发送,就是接收方接收之前,发送方一直阻塞
- 非阻塞发送,就是发送完了之后不管有没有被收到,继续干别的
- 阻塞接收,就是接收方遇到新的消息之前,一直守株待兔
- 非阻塞接收,就是一直在接收,但接收到的可能是空的消息
缓冲区
要实现非阻塞的发送,需要借助消息队列,或者消息缓冲。

环形缓冲区的图要看得懂才行。
杂项
- 消息传递系统要考虑到丢包问题,以及争抢(scramble)问题
- 还要考虑安全性(security),比如 SSL 对通信内容是有加密的
- 反正就是要可靠(reliable)。可靠的协议可能会使用 sequence numbers、timeouts、acks、retrans mission 等策略来确保消息正确传递